 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChessMix: Spatial Context Data Augmentation for Remote Sensing Semantic Segmentation
Paper and Code


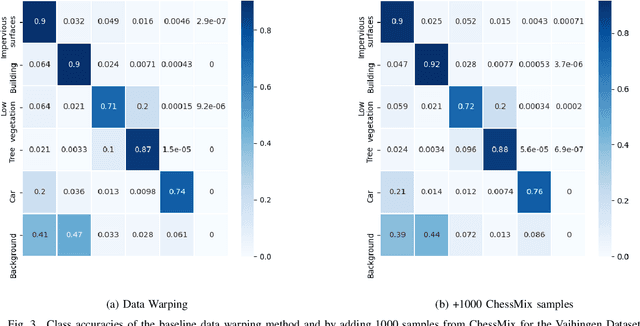
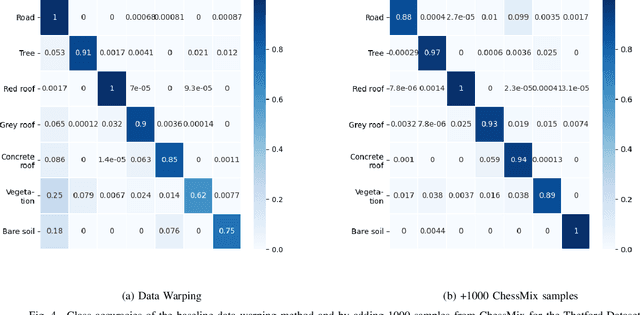
Labeling semantic segmentation datasets is a costly and laborious process if compared with tasks like image classification and object detection. This is especially true for remote sensing applications that not only work with extremely high spatial resolution data but also commonly require the knowledge of experts of the area to perform the manual labeling. Data augmentation techniques help to improve deep learning models under the circumstance of few and imbalanced labeled samples. In this work, we propose a novel data augmentation method focused on exploring the spatial context of remote sensing semantic segmentation. This method, ChessMix, creates new synthetic images from the existing training set by mixing transformed mini-patches across the dataset in a chessboard-like grid. ChessMix prioritizes patches with more examples of the rarest classes to alleviate the imbalance problems. The results in three diverse well-known remote sensing datasets show that this is a promising approach that helps to improve the networks' performance, working especially well in datasets with few available data. The results also show that ChessMix is capable of improving the segmentation of objects with few labeled pixels when compared to the most common data augmentation methods widely used.