 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Feature Engineering for Japanese Word Segmentation
Paper and Code
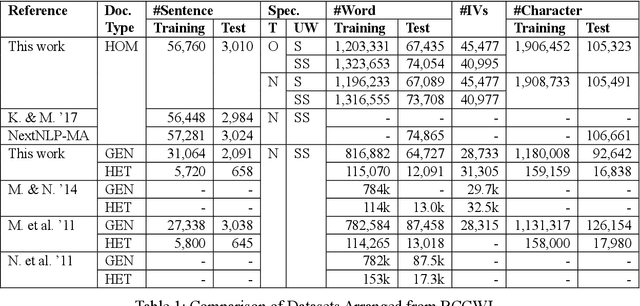
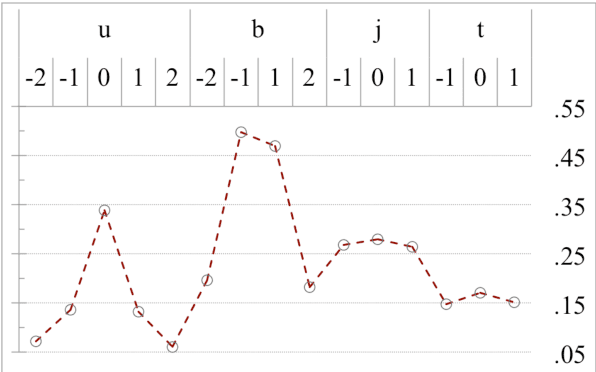
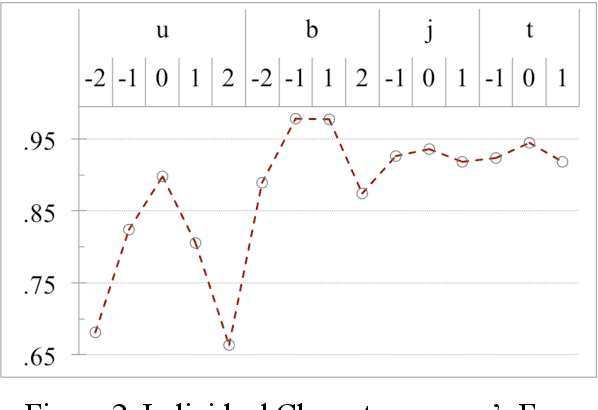
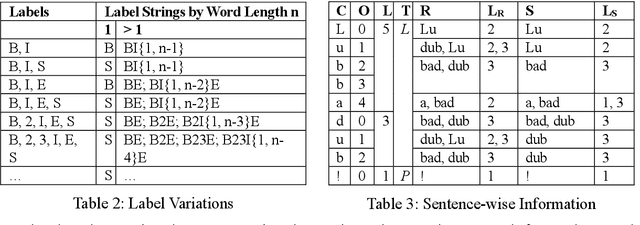
On word segmentation problems, machine learning architecture engineering often draws attention. The problem representation itself, however, has remained almost static as either word lattice ranking or character sequence tagging, for at least two decades. The latter of-ten shows stronger predictive power than the former for out-of-vocabulary (OOV) issue. When the issue escalating to rapid adaptation, which is a common scenario for industrial applications, active learning of partial annotations or re-training with additional lexical re-sources is usually applied, however, from a somewhat word-based perspective. Not only it is uneasy for end-users to comply with linguistically consistent word boundary decisions, but also the risk/cost of forking models permanently with estimated weights is seldom affordable. To overcome the obstacle, this work provides an alternative, which uses linguistic intuition about character compositions, such that a sophisticated feature set and its derived scheme can enable dynamic lexicon expansion with the model remaining intact. Experiment results suggest that the proposed solution, with or without external lexemes, performs competitively in terms of F1 score and OOV recall across various datasets.