 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Autoregressive Entropy Models for Learned Image Compression
Paper and Code
Jul 17, 2020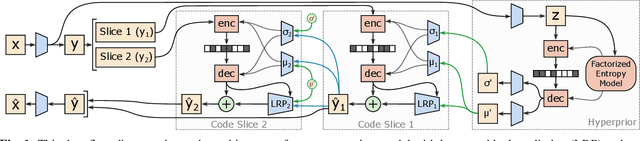



In learning-based approaches to image compression, codecs are developed by optimizing a computational model to minimize a rate-distortion objective. Currently, the most effective learned image codecs take the form of an entropy-constrained autoencoder with an entropy model that uses both forward and backward adaptation. Forward adaptation makes use of side information and can be efficiently integrated into a deep neural network. In contrast, backward adaptation typically makes predictions based on the causal context of each symbol, which requires serial processing that prevents efficient GPU / TPU utilization. We introduce two enhancements, channel-conditioning and latent residual prediction, that lead to network architectures with better rate-distortion performance than existing context-adaptive models while minimizing serial processing. Empirically, we see an average rate savings of 6.7% on the Kodak image set and 11.4% on the Tecnick image set compared to a context-adaptive baseline model. At low bit rates, where the improvements are most effective, our model saves up to 18% over the baseline and outperforms hand-engineered codecs like BPG by up to 25%.