 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCeci n'est pas une pomme: Adversarial Illusions in Multi-Modal Embeddings
Paper and Code
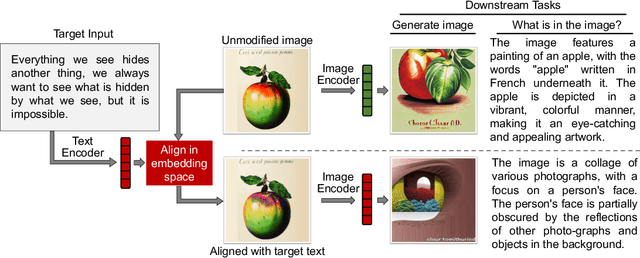



Multi-modal encoders map images, sounds, texts, videos, etc. into a single embedding space, aligning representations across modalities (e.g., associate an image of a dog with a barking sound). We show that multi-modal embeddings can be vulnerable to an attack we call "adversarial illusions." Given an input in any modality, an adversary can perturb it so as to make its embedding close to that of an arbitrary, adversary-chosen input in another modality. Illusions thus enable the adversary to align any image with any text, any text with any sound, etc. Adversarial illusions exploit proximity in the embedding space and are thus agnostic to downstream tasks. Using ImageBind embeddings, we demonstrate how adversarially aligned inputs, generated without knowledge of specific downstream tasks, mislead image generation, text generation, and zero-shot classification.