 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Reasoning in Simulation for Structure and Transfer Learning of Robot Manipulation Policies
Paper and Code
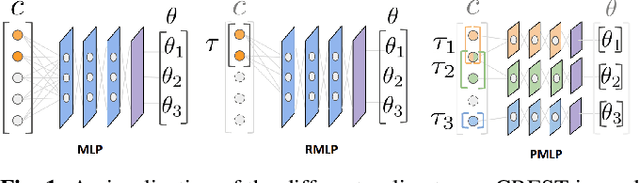

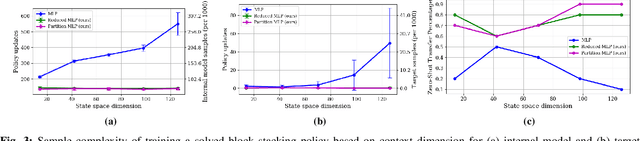
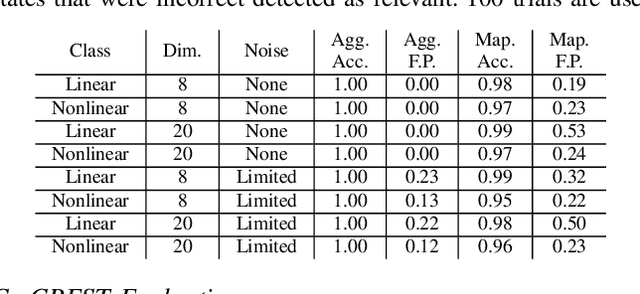
We present CREST, an approach for causal reasoning in simulation to learn the relevant state space for a robot manipulation policy. Our approach conducts interventions using internal models, which are simulations with approximate dynamics and simplified assumptions. These interventions elicit the structure between the state and action spaces, enabling construction of neural network policies with only relevant states as input. These policies are pretrained using the internal model with domain randomization over the relevant states. The policy network weights are then transferred to the target domain (e.g., the real world) for fine tuning. We perform extensive policy transfer experiments in simulation for two representative manipulation tasks: block stacking and crate opening. Our policies are shown to be more robust to domain shifts, more sample efficient to learn, and scale to more complex settings with larger state spaces. We also show improved zero-shot sim-to-real transfer of our policies for the block stacking task.