 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Campbell-Goodhart's law and Reinforcement Learning
Paper and Code
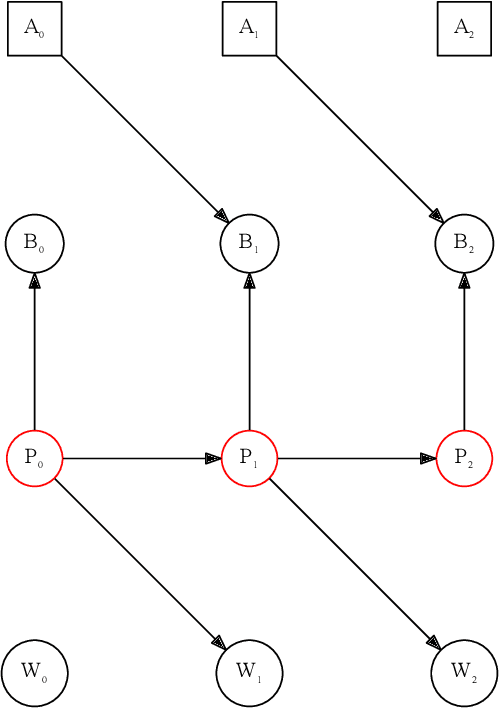


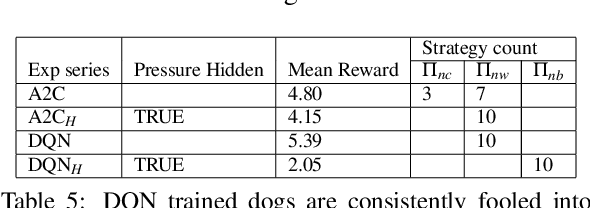
Campbell-Goodhart's law relates to the causal inference error whereby decision-making agents aim to influence variables which are correlated to their goal objective but do not reliably cause it. This is a well known error in Economics and Political Science but not widely labelled in Artificial Intelligence research. Through a simple example, we show how off-the-shelf deep Reinforcement Learning (RL) algorithms are not necessarily immune to this cognitive error. The off-policy learning method is tricked, whilst the on-policy method is not. The practical implication is that naive application of RL to complex real life problems can result in the same types of policy errors that humans make. Great care should be taken around understanding the causal model that underpins a solution derived from Reinforcement Learning.