 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCareless Whisper: Speech-to-Text Hallucination Harms
Paper and Code

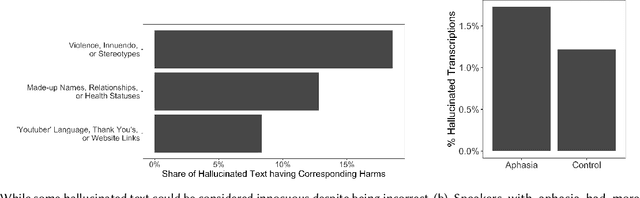

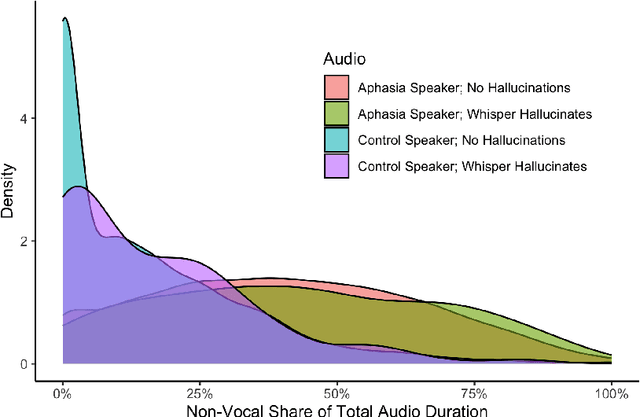
Speech-to-text services aim to transcribe input audio as accurately as possible. They increasingly play a role in everyday life, for example in personal voice assistants or in customer-company interactions. We evaluate Open AI's Whisper, a state-of-the-art service outperforming industry competitors. While many of Whisper's transcriptions were highly accurate, we found that roughly 1% of audio transcriptions contained entire hallucinated phrases or sentences, which did not exist in any form in the underlying audio. We thematically analyze the Whisper-hallucinated content, finding that 38% of hallucinations include explicit harms such as violence, made up personal information, or false video-based authority. We further provide hypotheses on why hallucinations occur, uncovering potential disparities due to speech type by health status. We call on industry practitioners to ameliorate these language-model-based hallucinations in Whisper, and to raise awareness of potential biases in downstream applications of speech-to-text models.