 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardinality Estimation in a Virtualized Network Device Using Online Machine Learning
Paper and Code



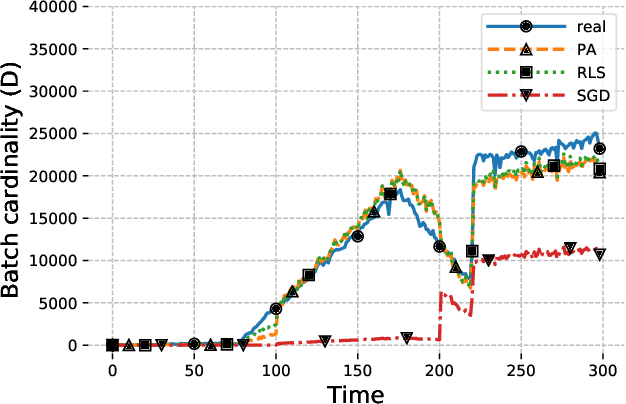
Cardinality estimation algorithms receive a stream of elements, with possible repetitions, and return the number of distinct elements in the stream. Such algorithms seek to minimize the required memory and CPU resource consumption at the price of inaccuracy in their output. In computer networks, cardinality estimation algorithms are mainly used for counting the number of distinct flows, and they are divided into two categories: sketching algorithms and sampling algorithms. Sketching algorithms require the processing of all packets, and they are therefore usually implemented by dedicated hardware. Sampling algorithms do not require processing of all packets, but they are known for their inaccuracy. In this work we identify one of the major drawbacks of sampling-based cardinality estimation algorithms: their inability to adapt to changes in flow size distribution. To address this problem, we propose a new sampling-based adaptive cardinality estimation framework, which uses online machine learning. We evaluate our framework using real traffic traces, and show significantly better accuracy compared to the best known sampling-based algorithms, for the same fraction of processed packets.