 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Style in Author and Document Representation
Paper and Code


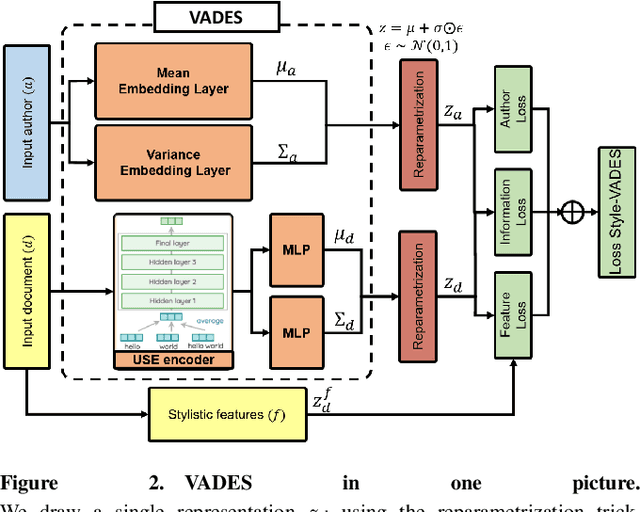

A wide range of Deep Natural Language Processing (NLP) models integrates continuous and low dimensional representations of words and documents. Surprisingly, very few models study representation learning for authors. These representations can be used for many NLP tasks, such as author identification and classification, or in recommendation systems. A strong limitation of existing works is that they do not explicitly capture writing style, making them hardly applicable to literary data. We therefore propose a new architecture based on Variational Information Bottleneck (VIB) that learns embeddings for both authors and documents with a stylistic constraint. Our model fine-tunes a pre-trained document encoder. We stimulate the detection of writing style by adding predefined stylistic features making the representation axis interpretable with respect to writing style indicators. We evaluate our method on three datasets: a literary corpus extracted from the Gutenberg Project, the Blog Authorship Corpus and IMDb62, for which we show that it matches or outperforms strong/recent baselines in authorship attribution while capturing much more accurately the authors stylistic aspects.