 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Q-learning solve Multi Armed Bantids?
Paper and Code
Oct 21, 2021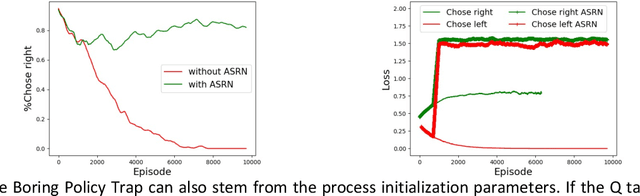
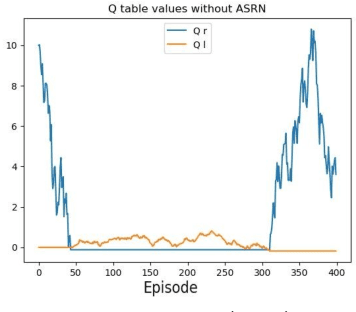
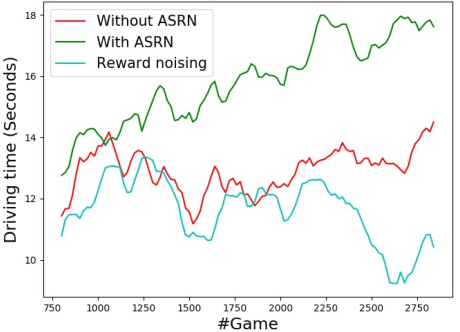
When a reinforcement learning (RL) method has to decide between several optional policies by solely looking at the received reward, it has to implicitly optimize a Multi-Armed-Bandit (MAB) problem. This arises the question: are current RL algorithms capable of solving MAB problems? We claim that the surprising answer is no. In our experiments we show that in some situations they fail to solve a basic MAB problem, and in many common situations they have a hard time: They suffer from regression in results during training, sensitivity to initialization and high sample complexity. We claim that this stems from variance differences between policies, which causes two problems: The first problem is the "Boring Policy Trap" where each policy have a different implicit exploration depends on its rewards variance, and leaving a boring, or low variance, policy is less likely due to its low implicit exploration. The second problem is the "Manipulative Consultant" problem, where value-estimation functions used in deep RL algorithms such as DQN or deep Actor Critic methods, maximize estimation precision rather than mean rewards, and have a better loss in low-variance policies, which cause the network to converge to a sub-optimal policy. Cognitive experiments on humans showed that noised reward signals may paradoxically improve performance. We explain this using the aforementioned problems, claiming that both humans and algorithms may share similar challenges in decision making. Inspired by this result, we propose the Adaptive Symmetric Reward Noising (ASRN) method, by which we mean equalizing the rewards variance across different policies, thus avoiding the two problems without affecting the environment's mean rewards behavior. We demonstrate that the ASRN scheme can dramatically improve the results.