Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical Nested NER with Large Language Model and UMLS Heuristics
Paper and Code
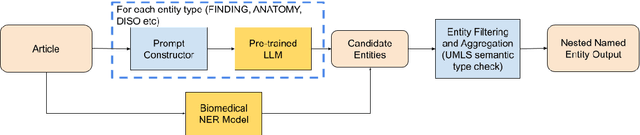



In this paper, we present our system for the BioNNE English track, which aims to extract 8 types of biomedical nested named entities from biomedical text. We use a large language model (Mixtral 8x7B instruct) and ScispaCy NER model to identify entities in an article and build custom heuristics based on unified medical language system (UMLS) semantic types to categorize the entities. We discuss the results and limitations of our system and propose future improvements. Our system achieved an F1 score of 0.39 on the BioNNE validation set and 0.348 on the test set.
* Submitted to CEUR-WS for the BioNNE task of BioASQ Lab in Conference
and Labs of the Evaluation Forum (CLEF) 2024 as a working note
View paper on