 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Bidirectional Insertion Representations for Documents
Paper and Code
Oct 29, 2019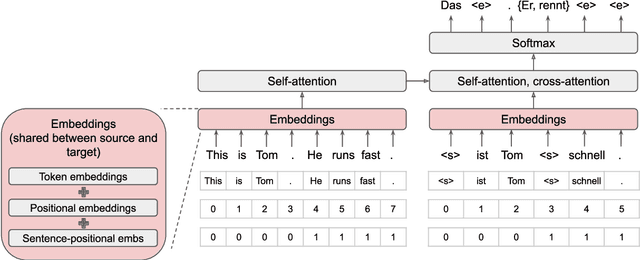
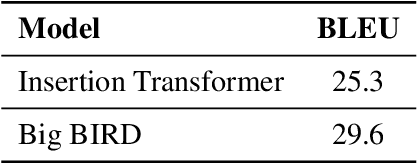

The Insertion Transformer is well suited for long form text generation due to its parallel generation capabilities, requiring $O(\log_2 n)$ generation steps to generate $n$ tokens. However, modeling long sequences is difficult, as there is more ambiguity captured in the attention mechanism. This work proposes the Big Bidirectional Insertion Representations for Documents (Big BIRD), an insertion-based model for document-level translation tasks. We scale up the insertion-based models to long form documents. Our key contribution is introducing sentence alignment via sentence-positional embeddings between the source and target document. We show an improvement of +4.3 BLEU on the WMT'19 English$\rightarrow$German document-level translation task compared with the Insertion Transformer baseline.