 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-LSTM Scoring Based Similarity Measurement with Agglomerative Hierarchical Clustering (AHC) for Speaker Diarization
Paper and Code
May 19, 2022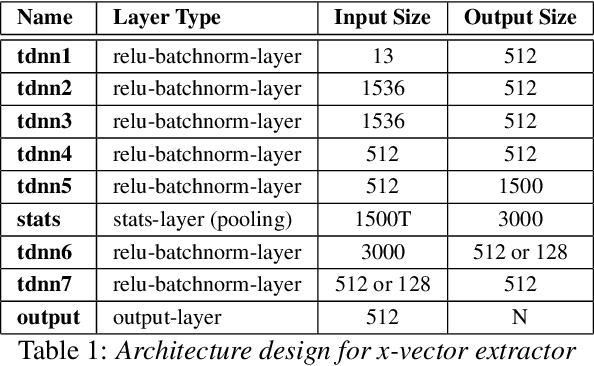
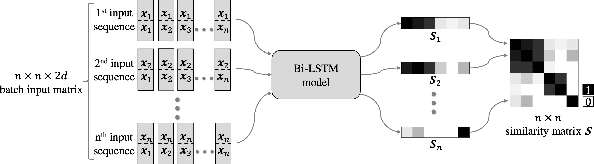
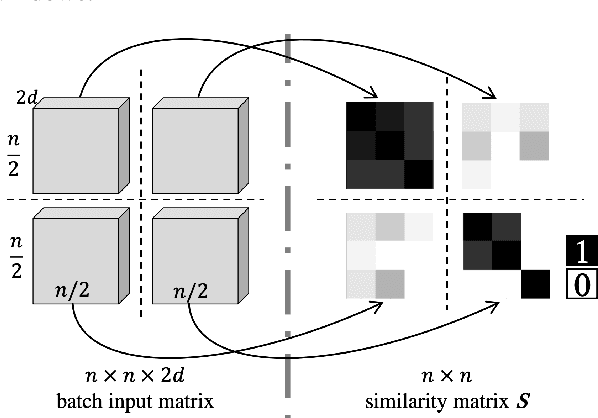

Majority of speech signals across different scenarios are never available with well-defined audio segments containing only a single speaker. A typical conversation between two speakers consists of segments where their voices overlap, interrupt each other or halt their speech in between multiple sentences. Recent advancements in diarization technology leverage neural network-based approaches to improvise multiple subsystems of speaker diarization system comprising of extracting segment-wise embedding features and detecting changes in the speaker during conversation. However, to identify speaker through clustering, models depend on methodologies like PLDA to generate similarity measure between two extracted segments from a given conversational audio. Since these algorithms ignore the temporal structure of conversations, they tend to achieve a higher Diarization Error Rate (DER), thus leading to misdetections both in terms of speaker and change identification. Therefore, to compare similarity of two speech segments both independently and sequentially, we propose a Bi-directional Long Short-term Memory network for estimating the elements present in the similarity matrix. Once the similarity matrix is generated, Agglomerative Hierarchical Clustering (AHC) is applied to further identify speaker segments based on thresholding. To evaluate the performance, Diarization Error Rate (DER%) metric is used. The proposed model achieves a low DER of 34.80% on a test set of audio samples derived from ICSI Meeting Corpus as compared to traditional PLDA based similarity measurement mechanism which achieved a DER of 39.90%.