Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Machine Learning: How Fast Can Your Algorithms Go?
Paper and Code
Jan 08, 2021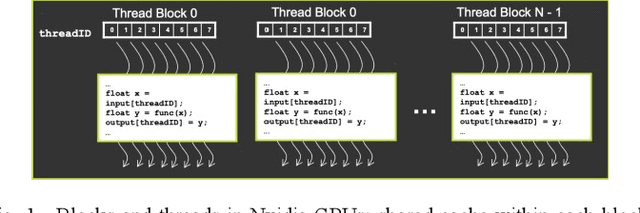
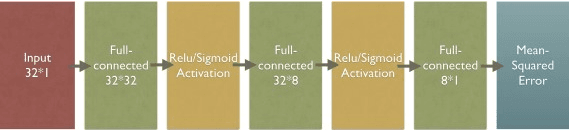
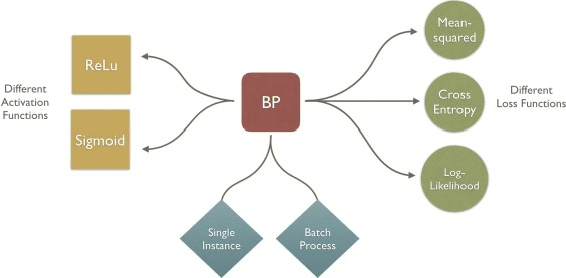
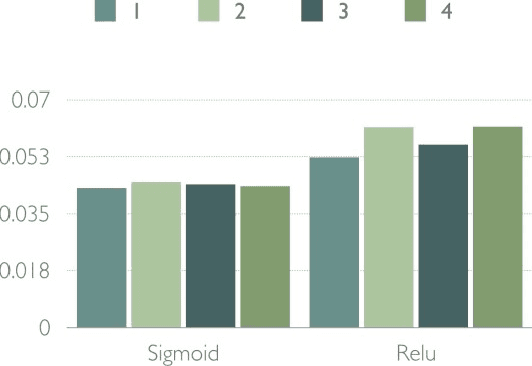
This paper is focused on evaluating the effect of some different techniques in machine learning speed-up, including vector caches, parallel execution, and so on. The following content will include some review of the previous approaches and our own experimental results.
View paper on