 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Neural Networks at Scale: A Performance Analysis and Pruning Study
Paper and Code
May 28, 2020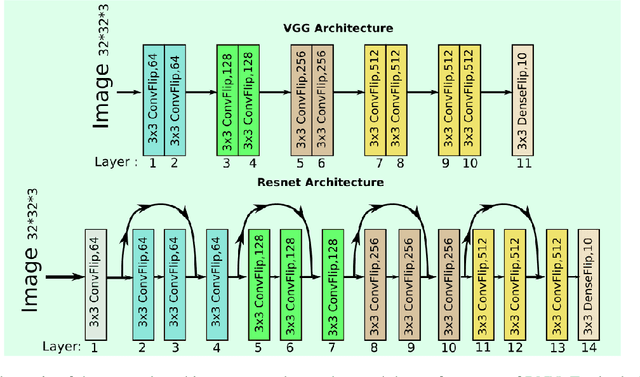
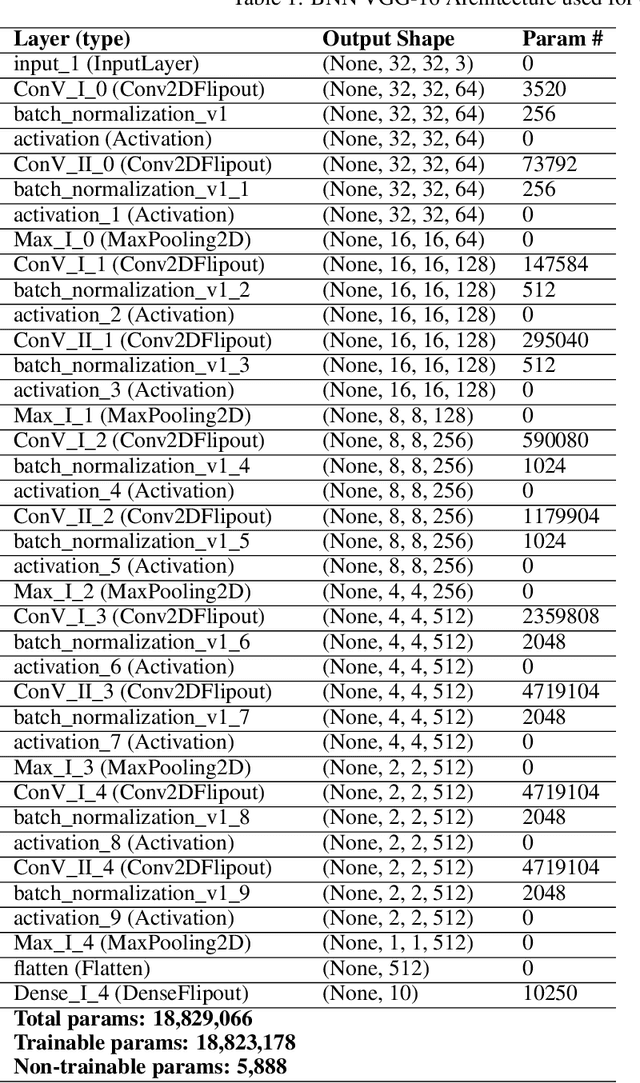
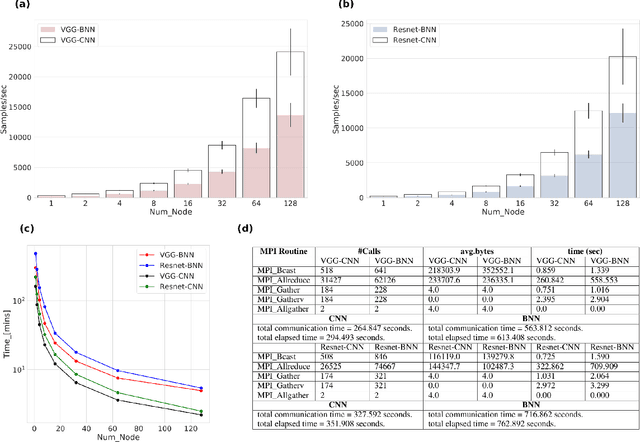
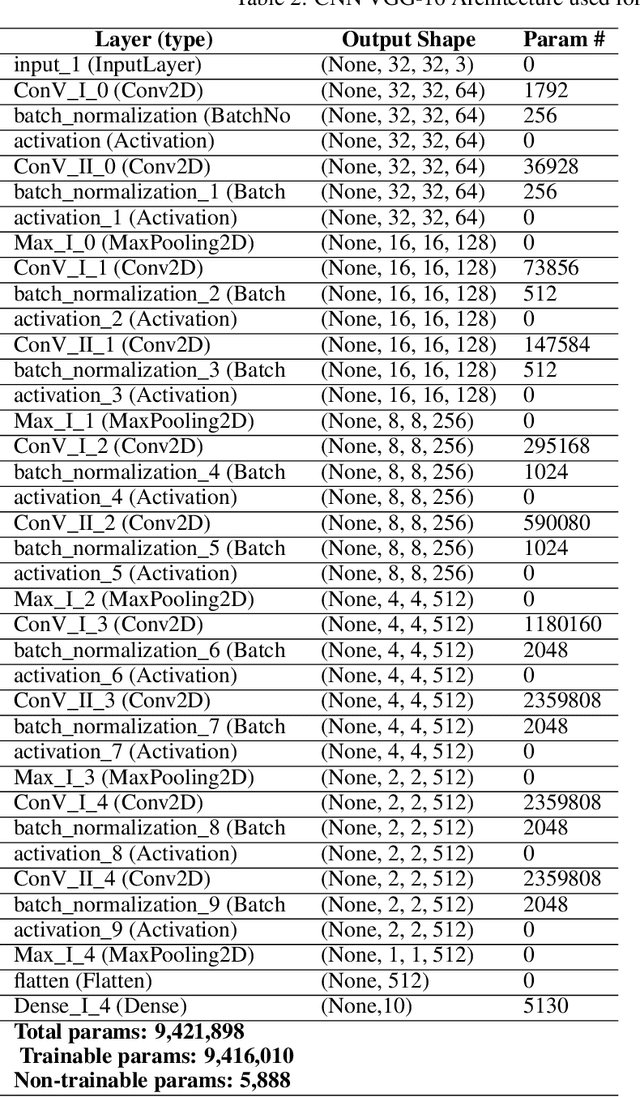
Bayesian neural Networks (BNNs) are a promising method of obtaining statistical uncertainties for neural network predictions but with a higher computational overhead which can limit their practical usage. This work explores the use of high performance computing with distributed training to address the challenges of training BNNs at scale. We present a performance and scalability comparison of training the VGG-16 and Resnet-18 models on a Cray-XC40 cluster. We demonstrate that network pruning can speed up inference without accuracy loss and provide an open source software package, {\it{BPrune}} to automate this pruning. For certain models we find that pruning up to 80\% of the network results in only a 7.0\% loss in accuracy. With the development of new hardware accelerators for Deep Learning, BNNs are of considerable interest for benchmarking performance. This analysis of training a BNN at scale outlines the limitations and benefits compared to a conventional neural network.