Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\bar{G}_{mst}$:An Unbiased Stratified Statistic and a Fast Gradient Optimization Algorithm Based on It
Paper and Code
Oct 07, 2021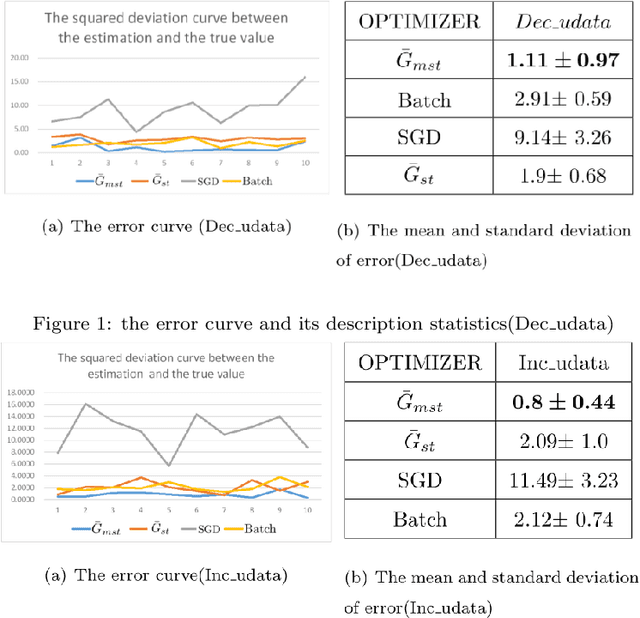
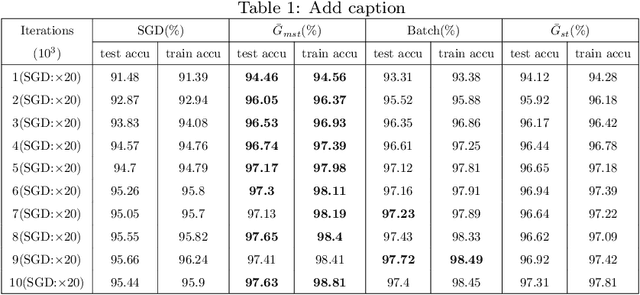
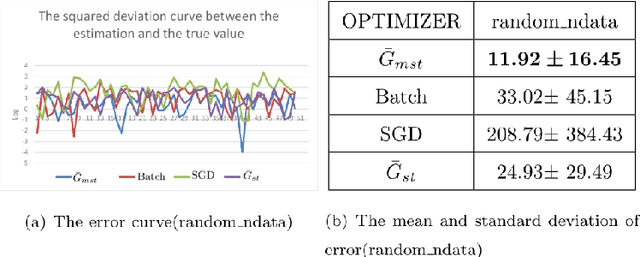
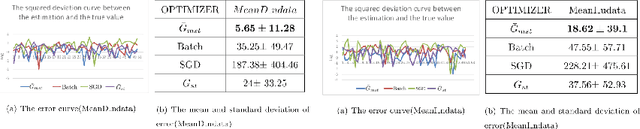
-The fluctuation effect of gradient expectation and variance caused by parameter update between consecutive iterations is neglected or confusing by current mainstream gradient optimization algorithms. The work in this paper remedy this issue by introducing a novel unbiased stratified statistic \ $\bar{G}_{mst}$\ , a sufficient condition of fast convergence for \ $\bar{G}_{mst}$\ also is established. A novel algorithm named MSSG designed based on \ $\bar{G}_{mst}$\ outperforms other sgd-like algorithms. Theoretical conclusions and experimental evidence strongly suggest to employ MSSG when training deep model.
View paper on