Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaIT: Barometer for Information Trustworthiness
Paper and Code
Jun 15, 2022
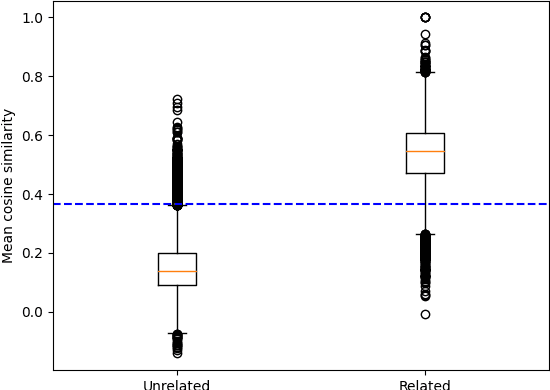
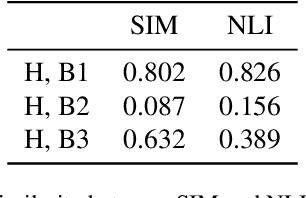
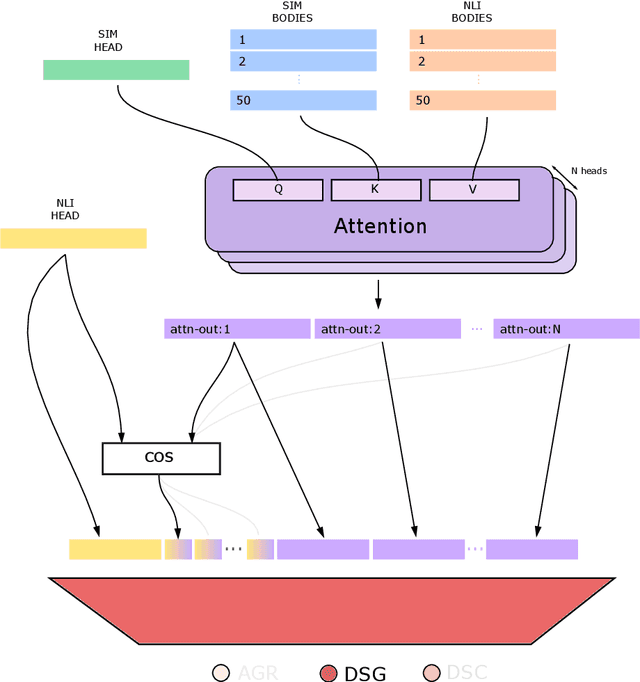
This paper presents a new approach to the FNC-1 fake news classification task which involves employing pre-trained encoder models from similar NLP tasks, namely sentence similarity and natural language inference, and two neural network architectures using this approach are proposed. Methods in data augmentation are explored as a means of tackling class imbalance in the dataset, employing common pre-existing methods and proposing a method for sample generation in the under-represented class using a novel sentence negation algorithm. Comparable overall performance with existing baselines is achieved, while significantly increasing accuracy on an under-represented but nonetheless important class for FNC-1.
View paper on