Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeautoNLP: NLP Feature Recommendations for Text Analytics Applications
Paper and Code
Feb 08, 2020
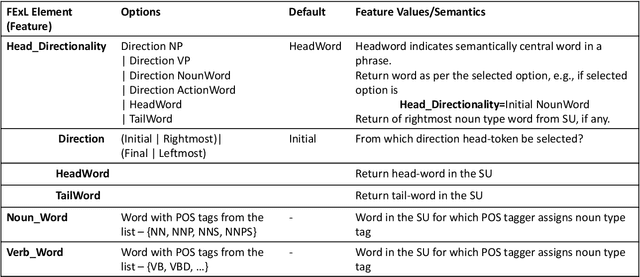
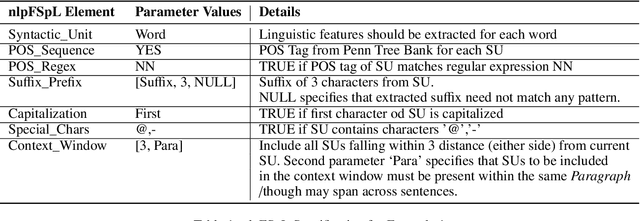

While designing machine learning based text analytics applications, often, NLP data scientists manually determine which NLP features to use based upon their knowledge and experience with related problems. This results in increased efforts during feature engineering process and renders automated reuse of features across semantically related applications inherently difficult. In this paper, we argue for standardization in feature specification by outlining structure of a language for specifying NLP features and present an approach for their reuse across applications to increase likelihood of identifying optimal features.
View paper on