Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Sampling of Geographic objects
Paper and Code
Apr 20, 2012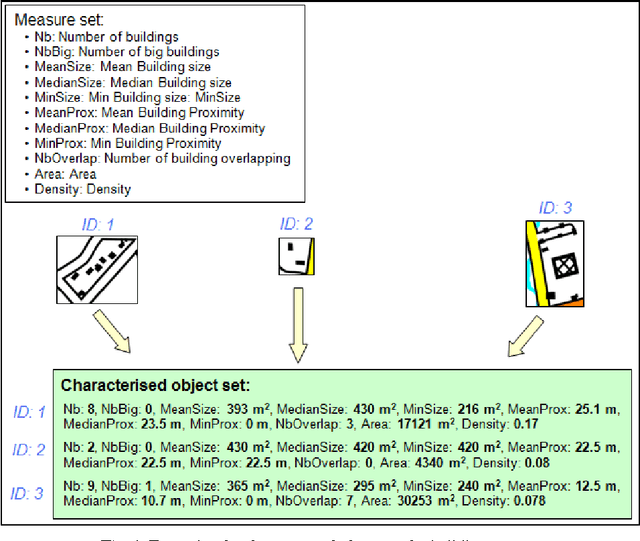
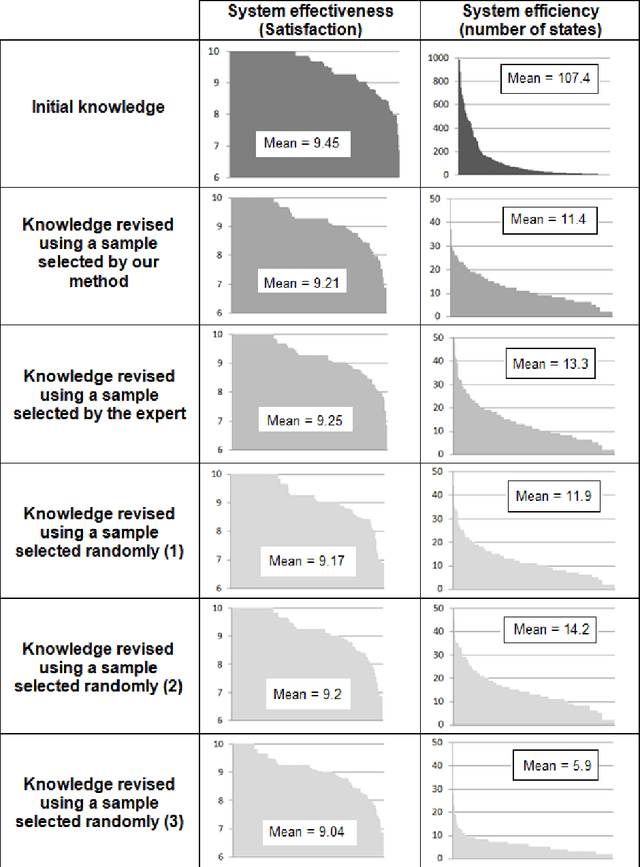
Today, one's disposes of large datasets composed of thousands of geographic objects. However, for many processes, which require the appraisal of an expert or much computational time, only a small part of these objects can be taken into account. In this context, robust sampling methods become necessary. In this paper, we propose a sampling method based on clustering techniques. Our method consists in dividing the objects in clusters, then in selecting in each cluster, the most representative objects. A case-study in the context of a process dedicated to knowledge revision for geographic data generalisation is presented. This case-study shows that our method allows to select relevant samples of objects.
* GIScience, Zurich : Switzerland (2010)
View paper on