 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Classifiers as Scientific Instruments: One Step Further Away from Ground-Truth
Paper and Code
Dec 19, 2018
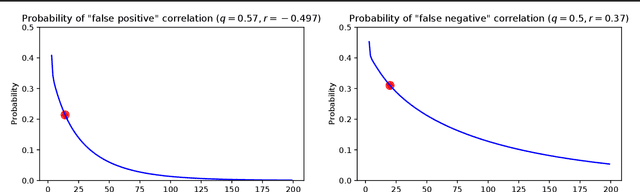

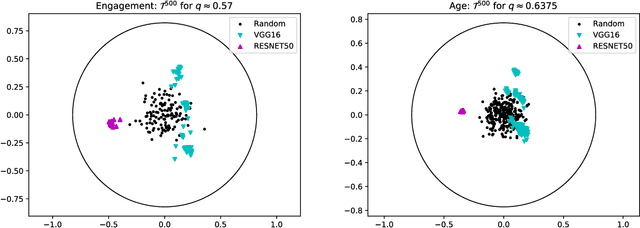
Automatic detectors of facial expression, gesture, affect, etc., can serve as scientific instruments to measure many behavioral and social phenomena (e.g., emotion, empathy, stress, engagement, etc.), and this has great potential to advance basic science. However, when a detector $d$ is trained to approximate an existing measurement tool (e.g., observation protocol, questionnaire), then care must be taken when interpreting measurements collected using $d$ since they are one step further removed from the underlying construct. We examine how the accuracy of $d$, as quantified by the correlation $q$ of $d$'s outputs with the ground-truth construct $U$, impacts the estimated correlation between $U$ (e.g., stress) and some other phenomenon $V$ (e.g., academic performance). In particular: (1) We show that if the true correlation between $U$ and $V$ is $r$, then the expected sample correlation, over all vectors $\mathcal{T}^n$ whose correlation with $U$ is $q$, is $qr$. (2) We derive a formula to compute the probability that the sample correlation (over $n$ subjects) using $d$ is positive, given that the true correlation between $U$ and $V$ is negative (and vice-versa). We show that this probability is non-negligible (around $10-15\%$) for values of $n$ and $q$ that have been used in recent affective computing studies. (3) With the goal to reduce the variance of correlations estimated by an automatic detector, we show empirically that training multiple neural networks $d^{(1)},\ldots,d^{(m)}$ using different training configurations (e.g., architectures, hyperparameters) for the same detection task provides only limited `coverage' of $\mathcal{T}^n$.