 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Transcription for Pre-Modern Japanese Kuzushiji Documents by Random Lines Erasure and Curriculum Learning
Paper and Code
May 06, 2020
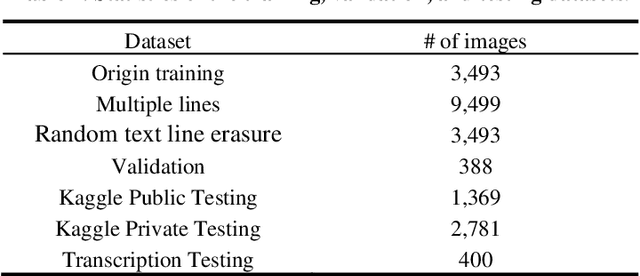
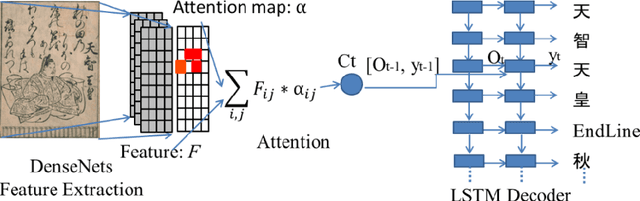

Recognizing the full-page of Japanese historical documents is a challenging problem due to the complex layout/background and difficulty of writing styles, such as cursive and connected characters. Most of the previous methods divided the recognition process into character segmentation and recognition. However, those methods provide only character bounding boxes and classes without text transcription. In this paper, we enlarge our previous humaninspired recognition system from multiple lines to the full-page of Kuzushiji documents. The human-inspired recognition system simulates human eye movement during the reading process. For the lack of training data, we propose a random text line erasure approach that randomly erases text lines and distorts documents. For the convergence problem of the recognition system for fullpage documents, we employ curriculum learning that trains the recognition system step by step from the easy level (several text lines of documents) to the difficult level (full-page documents). We tested the step training approach and random text line erasure approach on the dataset of the Kuzushiji recognition competition on Kaggle. The results of the experiments demonstrate the effectiveness of our proposed approaches. These results are competitive with other participants of the Kuzushiji recognition competition.