 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Sizing and Training of Efficient Deep Autoencoders using Second Order Algorithms
Paper and Code
Aug 11, 2023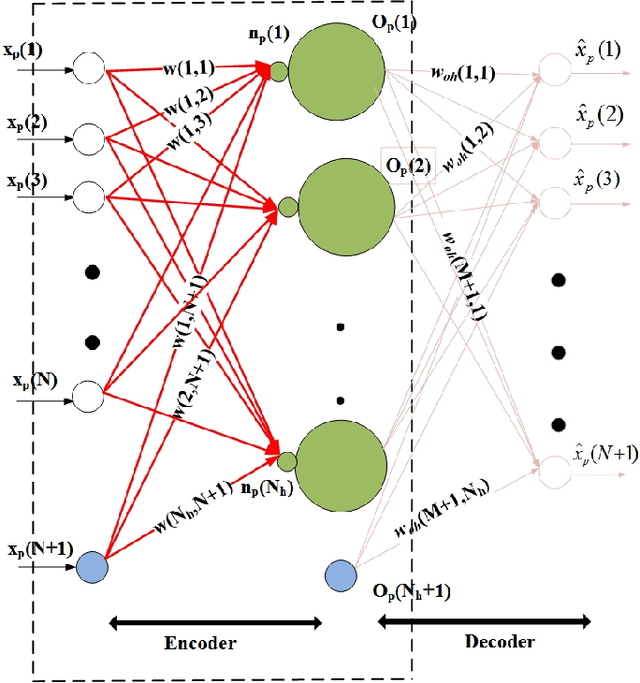
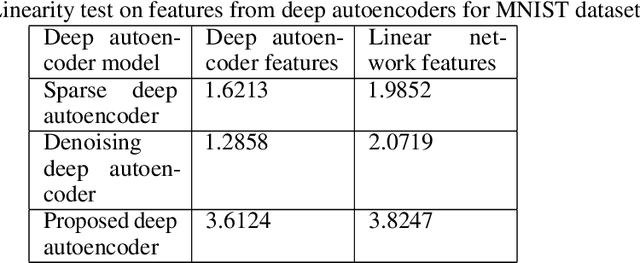
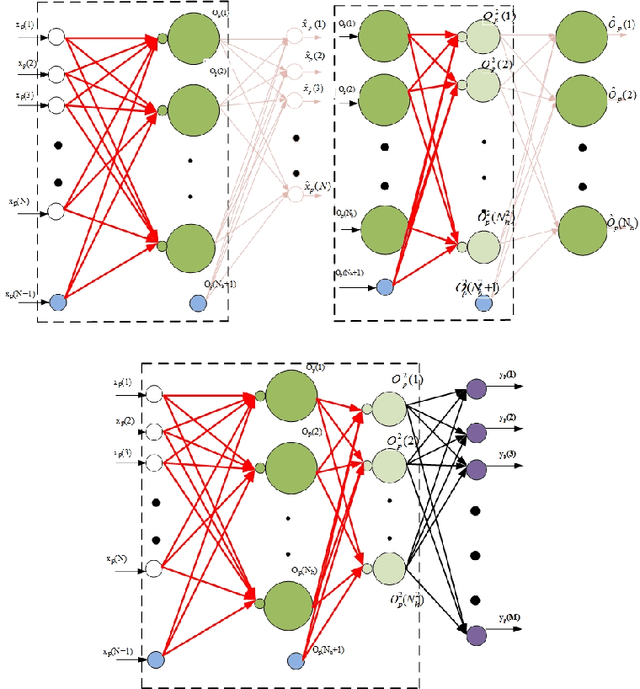
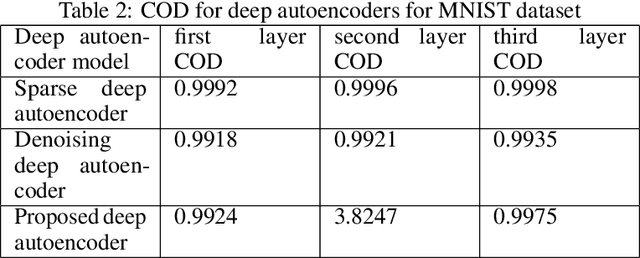
We propose a multi-step training method for designing generalized linear classifiers. First, an initial multi-class linear classifier is found through regression. Then validation error is minimized by pruning of unnecessary inputs. Simultaneously, desired outputs are improved via a method similar to the Ho-Kashyap rule. Next, the output discriminants are scaled to be net functions of sigmoidal output units in a generalized linear classifier. We then develop a family of batch training algorithm for the multi layer perceptron that optimizes its hidden layer size and number of training epochs. Next, we combine pruning with a growing approach. Later, the input units are scaled to be the net function of the sigmoidal output units that are then feed into as input to the MLP. We then propose resulting improvements in each of the deep learning blocks thereby improving the overall performance of the deep architecture. We discuss the principles and formulation regarding learning algorithms for deep autoencoders. We investigate several problems in deep autoencoders networks including training issues, the theoretical, mathematical and experimental justification that the networks are linear, optimizing the number of hidden units in each layer and determining the depth of the deep learning model. A direct implication of the current work is the ability to construct fast deep learning models using desktop level computational resources. This, in our opinion, promotes our design philosophy of building small but powerful algorithms. Performance gains are demonstrated at each step. Using widely available datasets, the final network's ten fold testing error is shown to be less than that of several other linear, generalized linear classifiers, multi layer perceptron and deep learners reported in the literature.