 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Repair of Neural Networks
Paper and Code
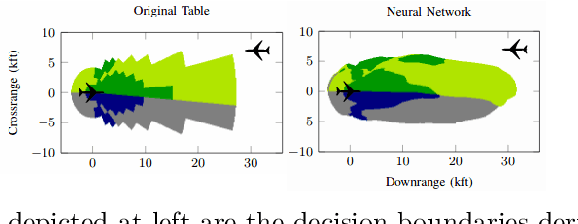
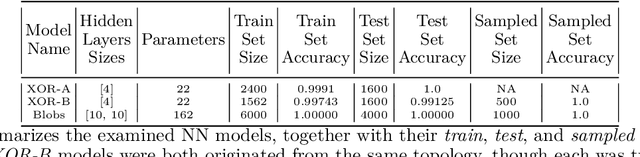


Over the last decade, Neural Networks (NNs) have been widely used in numerous applications including safety-critical ones such as autonomous systems. Despite their emerging adoption, it is well known that NNs are susceptible to Adversarial Attacks. Hence, it is highly important to provide guarantees that such systems work correctly. To remedy these issues we introduce a framework for repairing unsafe NNs w.r.t. safety specification, that is by utilizing satisfiability modulo theories (SMT) solvers. Our method is able to search for a new, safe NN representation, by modifying only a few of its weight values. In addition, our technique attempts to maximize the similarity to original network with regard to its decision boundaries. We perform extensive experiments which demonstrate the capability of our proposed framework to yield safe NNs w.r.t. the Adversarial Robustness property, with only a mild loss of accuracy (in terms of similarity). Moreover, we compare our method with a naive baseline to empirically prove its effectiveness. To conclude, we provide an algorithm to automatically repair NNs given safety properties, and suggest a few heuristics to improve its computational performance. Currently, by following this approach we are capable of producing small-sized (i.e., with up to few hundreds of parameters) correct NNs, composed of the piecewise linear ReLU activation function. Nevertheless, our framework is general in the sense that it can synthesize NNs w.r.t. any decidable fragment of first-order logic specification.