Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Heterogeneous Low-Bit Quantization of Multi-Model Deep Learning Inference Pipeline
Paper and Code
Nov 10, 2023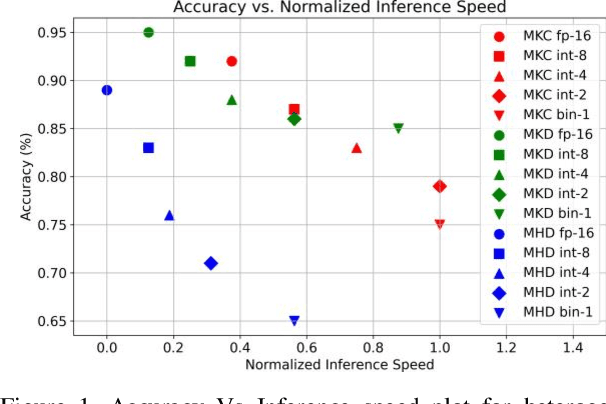
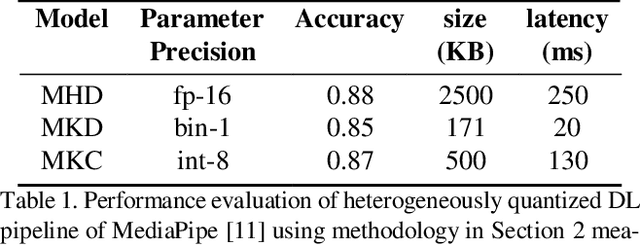
Multiple Deep Neural Networks (DNNs) integrated into single Deep Learning (DL) inference pipelines e.g. Multi-Task Learning (MTL) or Ensemble Learning (EL), etc., albeit very accurate, pose challenges for edge deployment. In these systems, models vary in their quantization tolerance and resource demands, requiring meticulous tuning for accuracy-latency balance. This paper introduces an automated heterogeneous quantization approach for DL inference pipelines with multiple DNNs.
* LBQNN@ICCV2023
View paper on