 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Efficient Linear Regression with Data-Dependent Sampling
Paper and Code
Oct 23, 2014
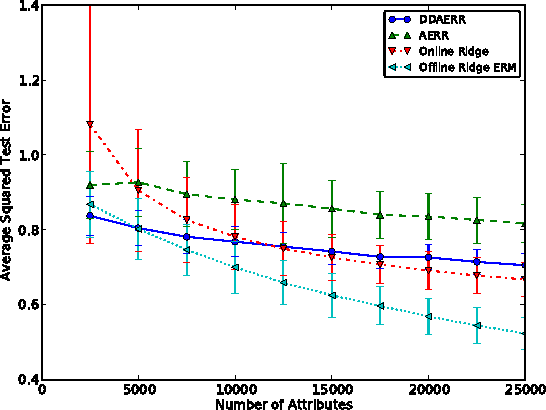
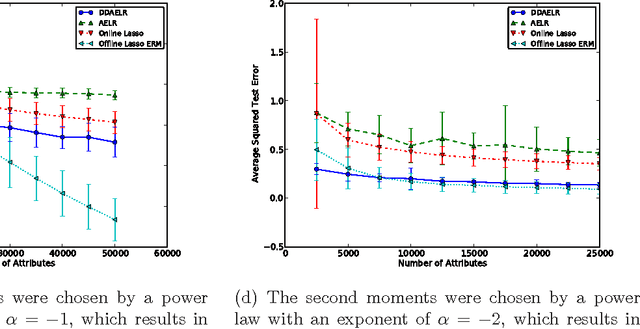
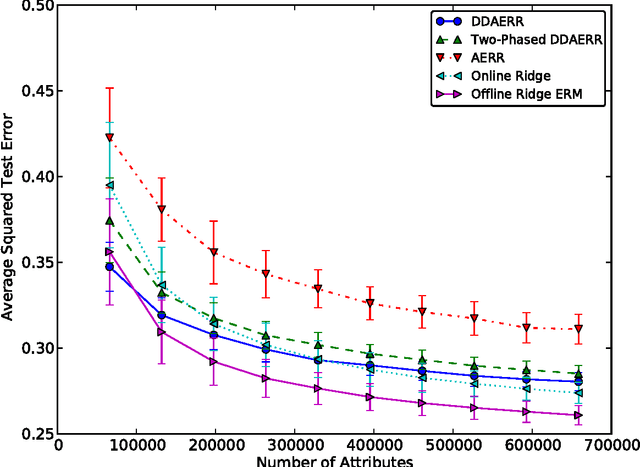
In this paper we analyze a budgeted learning setting, in which the learner can only choose and observe a small subset of the attributes of each training example. We develop efficient algorithms for ridge and lasso linear regression, which utilize the geometry of the data by a novel data-dependent sampling scheme. When the learner has prior knowledge on the second moments of the attributes, the optimal sampling probabilities can be calculated precisely, and result in data-dependent improvements factors for the excess risk over the state-of-the-art that may be as large as $O(\sqrt{d})$, where $d$ is the problem's dimension. Moreover, under reasonable assumptions our algorithms can use less attributes than full-information algorithms, which is the main concern in budgeted learning settings. To the best of our knowledge, these are the first algorithms able to do so in our setting. Where no such prior knowledge is available, we develop a simple estimation technique that given a sufficient amount of training examples, achieves similar improvements. We complement our theoretical analysis with experiments on several data sets which support our claims.