 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Driven Multi-Modal Fusion: Enhancing Sign Language Recognition and Translation
Paper and Code
Sep 06, 2023

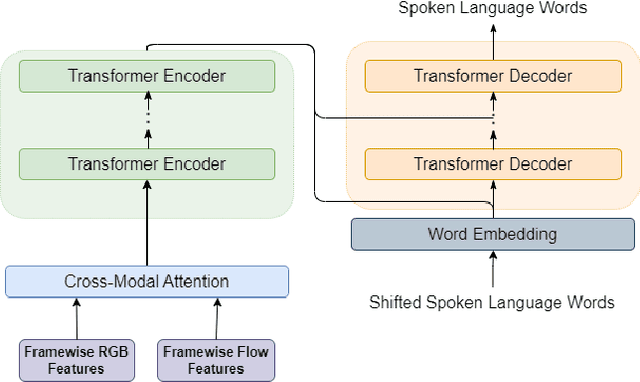

In this paper, we devise a mechanism for the addition of multi-modal information with an existing pipeline for continuous sign language recognition and translation. In our procedure, we have incorporated optical flow information with RGB images to enrich the features with movement-related information. This work studies the feasibility of such modality inclusion using a cross-modal encoder. The plugin we have used is very lightweight and doesn't need to include a separate feature extractor for the new modality in an end-to-end manner. We have applied the changes in both sign language recognition and translation, improving the result in each case. We have evaluated the performance on the RWTH-PHOENIX-2014 dataset for sign language recognition and the RWTH-PHOENIX-2014T dataset for translation. On the recognition task, our approach reduced the WER by 0.9, and on the translation task, our approach increased most of the BLEU scores by ~0.6 on the test set.