 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotics of Wide Convolutional Neural Networks
Paper and Code
Aug 19, 2020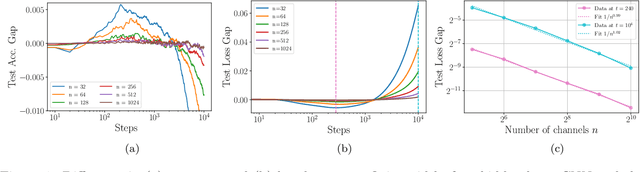
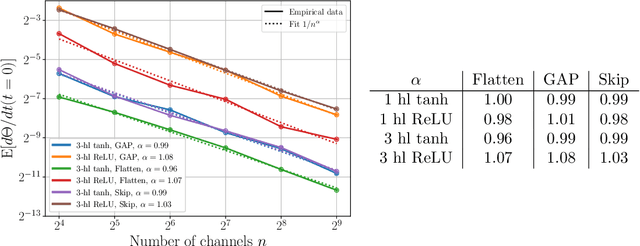
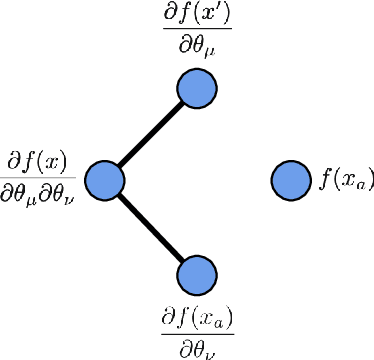
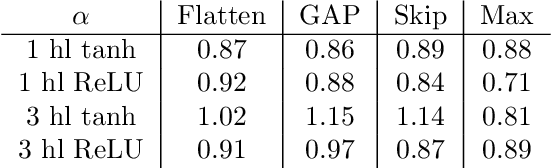
Wide neural networks have proven to be a rich class of architectures for both theory and practice. Motivated by the observation that finite width convolutional networks appear to outperform infinite width networks, we study scaling laws for wide CNNs and networks with skip connections. Following the approach of (Dyer & Gur-Ari, 2019), we present a simple diagrammatic recipe to derive the asymptotic width dependence for many quantities of interest. These scaling relationships provide a solvable description for the training dynamics of wide convolutional networks. We test these relations across a broad range of architectures. In particular, we find that the difference in performance between finite and infinite width models vanishes at a definite rate with respect to model width. Nonetheless, this relation is consistent with finite width models generalizing either better or worse than their infinite width counterparts, and we provide examples where the relative performance depends on the optimization details.