 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Effectiveness of Using Internal Signals for Check-Worthy Claim Identification in Unlabeled Data for Automated Fact-Checking
Paper and Code

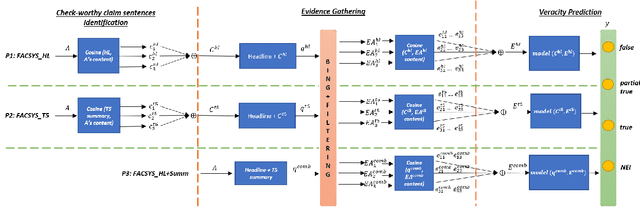
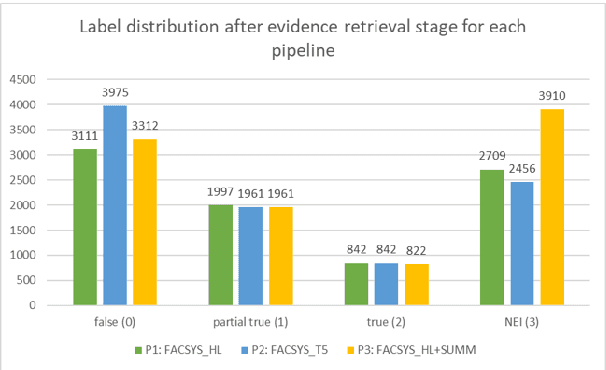
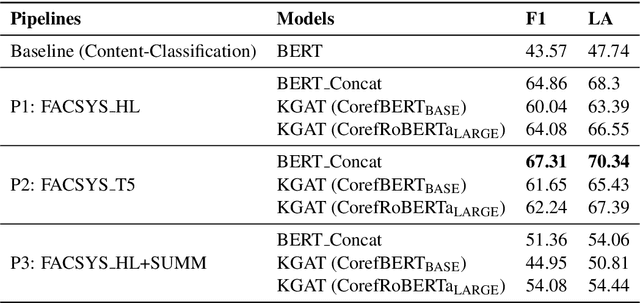
While recent work on automated fact-checking has focused mainly on verifying and explaining claims, for which the list of claims is readily available, identifying check-worthy claim sentences from a text remains challenging. Current claim identification models rely on manual annotations for each sentence in the text, which is an expensive task and challenging to conduct on a frequent basis across multiple domains. This paper explores methodology to identify check-worthy claim sentences from fake news articles, irrespective of domain, without explicit sentence-level annotations. We leverage two internal supervisory signals - headline and the abstractive summary - to rank the sentences based on semantic similarity. We hypothesize that this ranking directly correlates to the check-worthiness of the sentences. To assess the effectiveness of this hypothesis, we build pipelines that leverage the ranking of sentences based on either the headline or the abstractive summary. The top-ranked sentences are used for the downstream fact-checking tasks of evidence retrieval and the article's veracity prediction by the pipeline. Our findings suggest that the top 3 ranked sentences contain enough information for evidence-based fact-checking of a fake news article. We also show that while the headline has more gisting similarity with how a fact-checking website writes a claim, the summary-based pipeline is the most promising for an end-to-end fact-checking system.