 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIBA: Towards Accurate and Robust Identification of Backdoor Attacks in Federated Learning
Paper and Code
Feb 09, 2022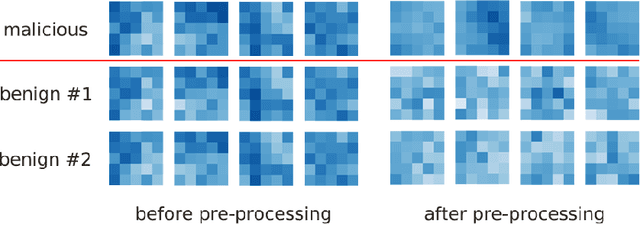


The distributed nature and privacy-preserving characteristics of federated learning make it prone to the threat of poisoning attacks, especially backdoor attacks, where the adversary implants backdoors to misguide the model on certain attacker-chosen sub-tasks. In this paper, we present a novel method ARIBA to accurately and robustly identify backdoor attacks in federated learning. By empirical study, we observe that backdoor attacks are discernible by the filters of CNN layers. Based on this finding, we employ unsupervised anomaly detection to evaluate the pre-processed filters and calculate an anomaly score for each client. We then identify the most suspicious clients according to their anomaly scores. Extensive experiments are conducted, which show that our method ARIBA can effectively and robustly defend against multiple state-of-the-art attacks without degrading model performance.