 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Explanations for Pattern-Based Text Classifiers
Paper and Code
May 22, 2022
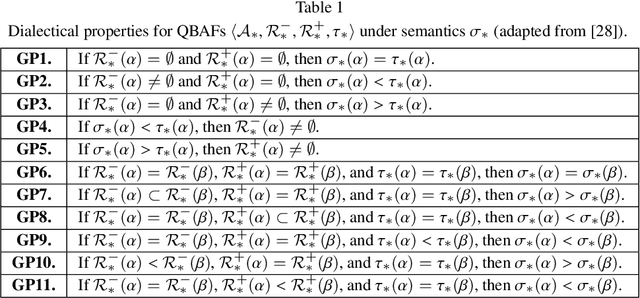


Recent works in Explainable AI mostly address the transparency issue of black-box models or create explanations for any kind of models (i.e., they are model-agnostic), while leaving explanations of interpretable models largely underexplored. In this paper, we fill this gap by focusing on explanations for a specific interpretable model, namely pattern-based logistic regression (PLR) for binary text classification. We do so because, albeit interpretable, PLR is challenging when it comes to explanations. In particular, we found that a standard way to extract explanations from this model does not consider relations among the features, making the explanations hardly plausible to humans. Hence, we propose AXPLR, a novel explanation method using (forms of) computational argumentation to generate explanations (for outputs computed by PLR) which unearth model agreements and disagreements among the features. Specifically, we use computational argumentation as follows: we see features (patterns) in PLR as arguments in a form of quantified bipolar argumentation frameworks (QBAFs) and extract attacks and supports between arguments based on specificity of the arguments; we understand logistic regression as a gradual semantics for these QBAFs, used to determine the arguments' dialectic strength; and we study standard properties of gradual semantics for QBAFs in the context of our argumentative re-interpretation of PLR, sanctioning its suitability for explanatory purposes. We then show how to extract intuitive explanations (for outputs computed by PLR) from the constructed QBAFs. Finally, we conduct an empirical evaluation and two experiments in the context of human-AI collaboration to demonstrate the advantages of our resulting AXPLR method.