 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Latent Vulnerabilities Hidden Gems for Software Vulnerability Prediction? An Empirical Study
Paper and Code
Jan 20, 2024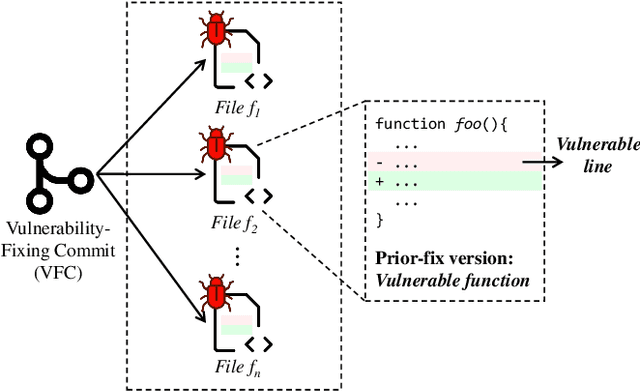



Collecting relevant and high-quality data is integral to the development of effective Software Vulnerability (SV) prediction models. Most of the current SV datasets rely on SV-fixing commits to extract vulnerable functions and lines. However, none of these datasets have considered latent SVs existing between the introduction and fix of the collected SVs. There is also little known about the usefulness of these latent SVs for SV prediction. To bridge these gaps, we conduct a large-scale study on the latent vulnerable functions in two commonly used SV datasets and their utilization for function-level and line-level SV predictions. Leveraging the state-of-the-art SZZ algorithm, we identify more than 100k latent vulnerable functions in the studied datasets. We find that these latent functions can increase the number of SVs by 4x on average and correct up to 5k mislabeled functions, yet they have a noise level of around 6%. Despite the noise, we show that the state-of-the-art SV prediction model can significantly benefit from such latent SVs. The improvements are up to 24.5% in the performance (F1-Score) of function-level SV predictions and up to 67% in the effectiveness of localizing vulnerable lines. Overall, our study presents the first promising step toward the use of latent SVs to improve the quality of SV datasets and enhance the performance of SV prediction tasks.