Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation capabilities of neural networks on unbounded domains
Paper and Code
Nov 06, 2019
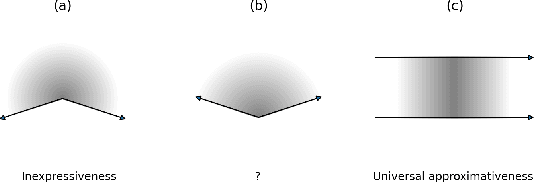
If $p \in (1, \infty)$ and if the activation function belongs to a monotone sigmoid, relu, elu, softplus or leaky relu, we prove that neural networks are universal approximators of $L^{p}(\mathbb{R} \times [0, 1]^n)$. This generalizes corresponding universal approximation theorems on $[0,1]^n.$ Moreover if $p \in (1, \infty)$ and if the activation function belongs to a sigmoid, relu, elu, softplus or leaky relu, we show that neural networks never represents non-zero functions in $L^{p}(\mathbb{R} \times \mathbb{R}^+)$ and $L^{p}(\mathbb{R}^2)$.
View paper on