 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaches of large-scale images recognition with more than 50,000 categoris
Paper and Code
Jul 26, 2020

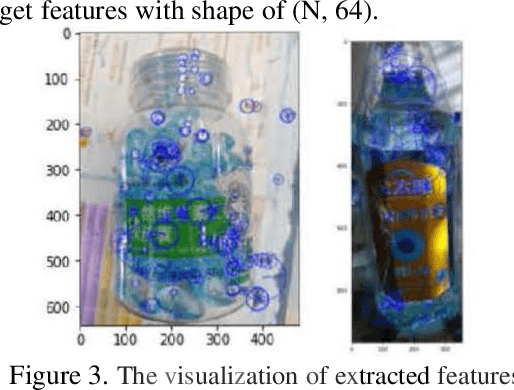
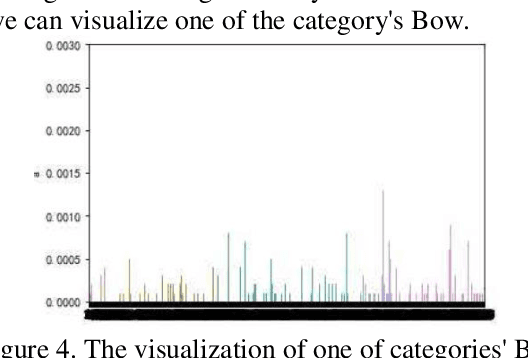
Though current CV models have been able to achieve high levels of accuracy on small-scale images classification dataset with hundreds or thousands of categories, many models become infeasible in computational or space consumption when it comes to large-scale dataset with more than 50,000 categories. In this paper, we provide a viable solution for classifying large-scale species datasets using traditional CV techniques such as.features extraction and processing, BOVW(Bag of Visual Words) and some statistical learning technics like Mini-Batch K-Means,SVM which are used in our works. And then mixed with a neural network model. When applying these techniques, we have done some optimization in time and memory consumption, so that it can be feasible for large-scale dataset. And we also use some technics to reduce the impact of mislabeling data. We use a dataset with more than 50, 000 categories, and all operations are done on common computer with l 6GB RAM and a CPU of 3. OGHz. Our contributions are: 1) analysis what problems may meet in the training processes, and presents several feasible ways to solve these problems. 2) Make traditional CV models combined with neural network models provide some feasible scenarios for training large-scale classified datasets within the constraints of time and spatial resources.