 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly localization by modeling perceptual features
Paper and Code
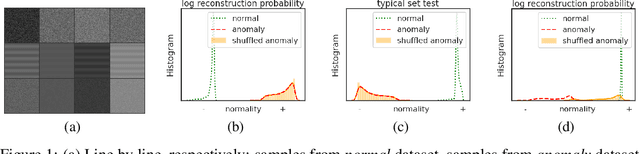
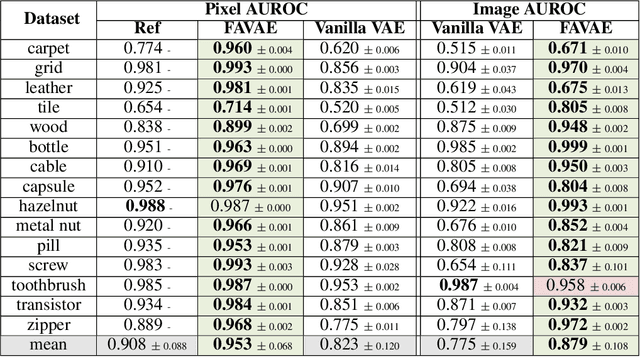
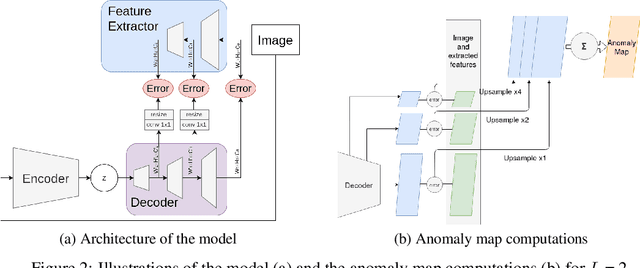

Although unsupervised generative modeling of an image dataset using a Variational AutoEncoder (VAE) has been used to detect anomalous images, or anomalous regions in images, recent works have shown that this method often identifies images or regions that do not concur with human perception, even questioning the usability of generative models for robust anomaly detection. Here, we argue that those issues can emerge from having a simplistic model of the anomaly distribution and we propose a new VAE-based model expressing a more complex anomaly model that is also closer to human perception. This Feature-Augmented VAE is trained by not only reconstructing the input image in pixel space, but also in several different feature spaces, which are computed by a convolutional neural network trained beforehand on a large image dataset. It achieves clear improvement over state-of-the-art methods on the MVTec anomaly detection and localization datasets.