Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAncient Korean Archive Translation: Comparison Analysis on Statistical phrase alignment, LLM in-context learning, and inter-methodological approach
Paper and Code
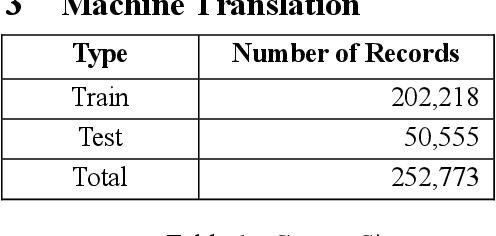
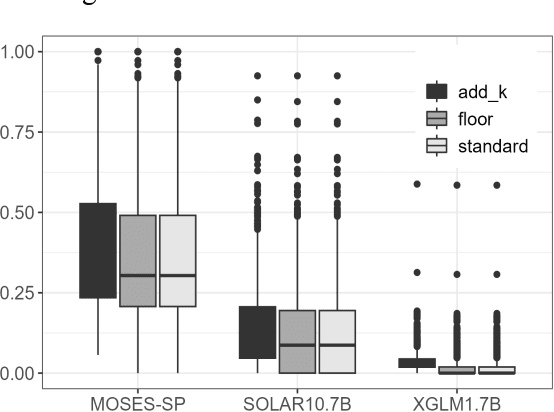
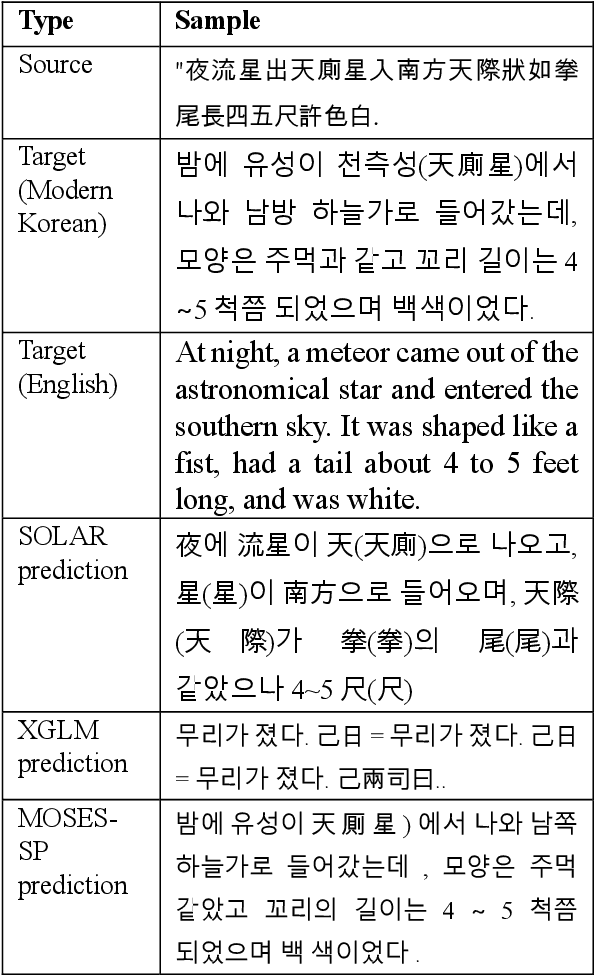
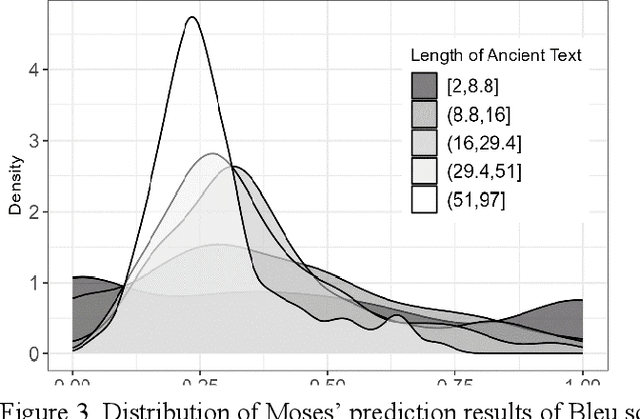
This study aims to compare three methods for translating ancient texts with sparse corpora: (1) the traditional statistical translation method of phrase alignment, (2) in-context LLM learning, and (3) proposed inter methodological approach - statistical machine translation method using sentence piece tokens derived from unified set of source-target corpus. The performance of the proposed approach in this study is 36.71 in BLEU score, surpassing the scores of SOLAR-10.7B context learning and the best existing Seq2Seq model. Further analysis and discussion are presented.
* ACL2024 submitted
View paper on