 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Statistical Hypothesis based Learning Mechanism for Faster Crawling
Paper and Code
Aug 13, 2012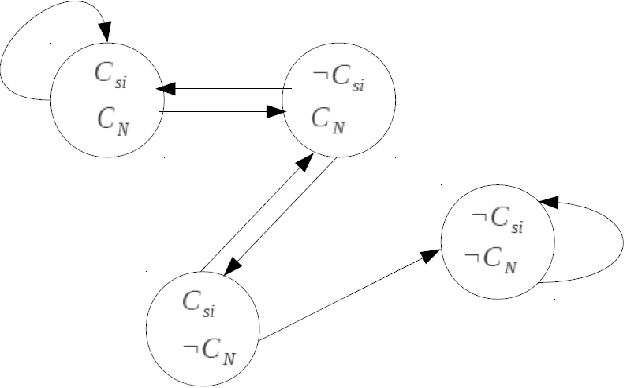
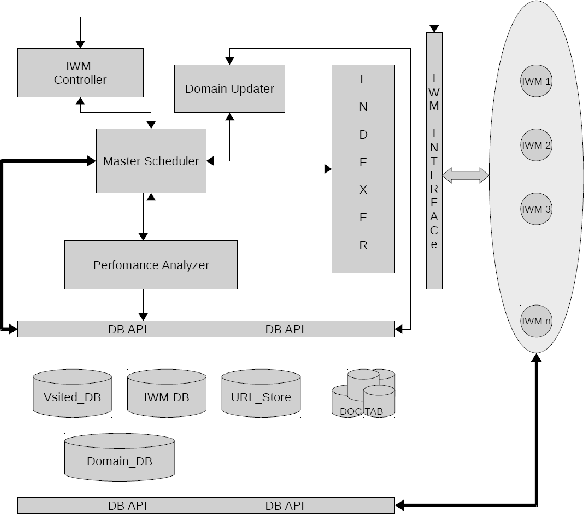
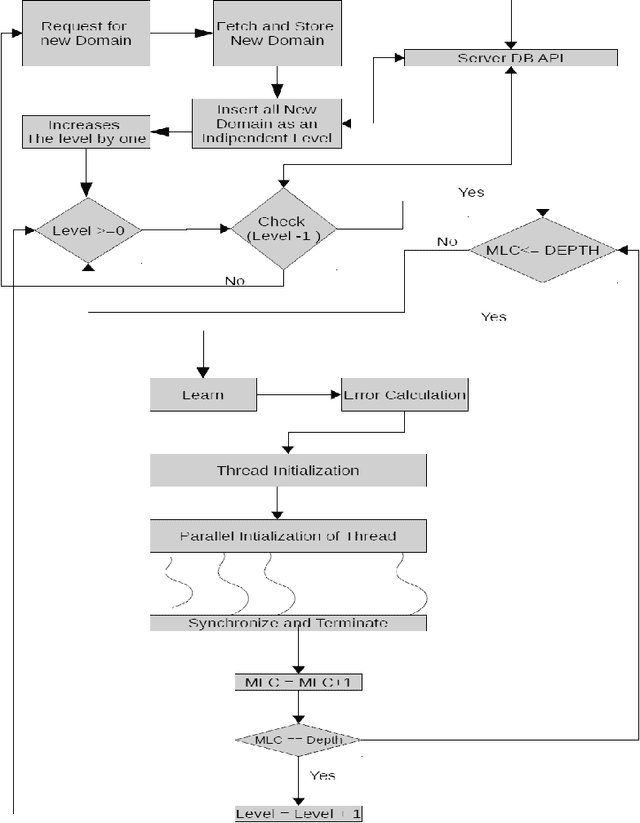
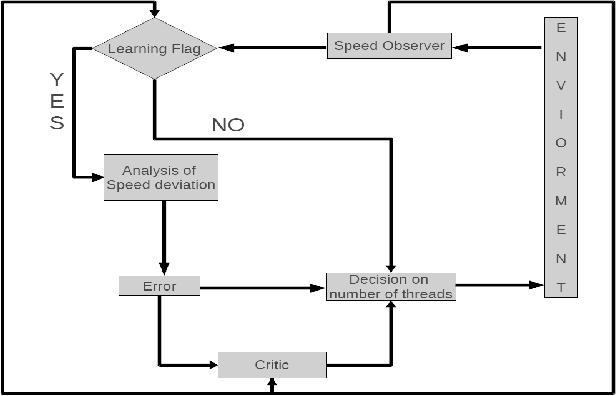
The growth of world-wide-web (WWW) spreads its wings from an intangible quantities of web-pages to a gigantic hub of web information which gradually increases the complexity of crawling process in a search engine. A search engine handles a lot of queries from various parts of this world, and the answers of it solely depend on the knowledge that it gathers by means of crawling. The information sharing becomes a most common habit of the society, and it is done by means of publishing structured, semi-structured and unstructured resources on the web. This social practice leads to an exponential growth of web-resource, and hence it became essential to crawl for continuous updating of web-knowledge and modification of several existing resources in any situation. In this paper one statistical hypothesis based learning mechanism is incorporated for learning the behavior of crawling speed in different environment of network, and for intelligently control of the speed of crawler. The scaling technique is used to compare the performance proposed method with the standard crawler. The high speed performance is observed after scaling, and the retrieval of relevant web-resource in such a high speed is analyzed.