 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of LLMs and Google Translate for translation of selected Indian languages via sentiment and semantic analyses
Paper and Code
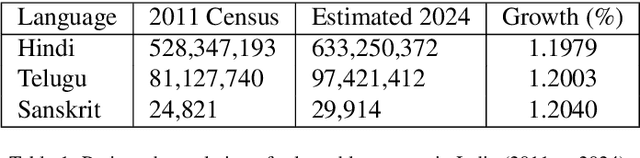
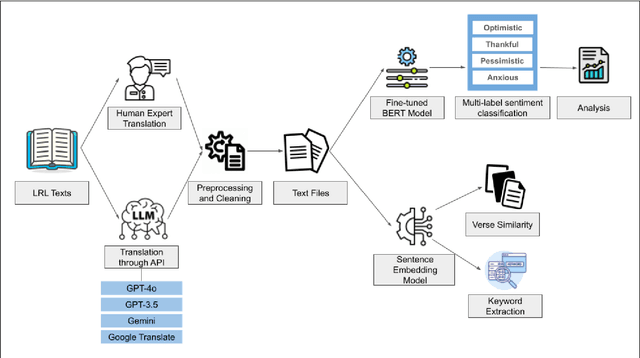

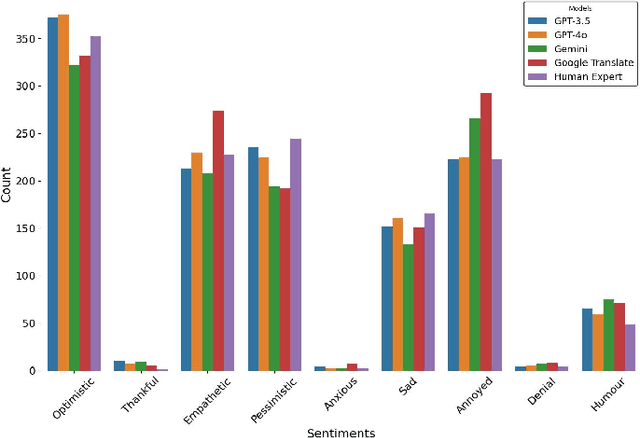
Large Language models (LLMs) have been prominent for language translation, including low-resource languages. There has been limited study about the assessment of the quality of translations generated by LLMs, including Gemini, GPT and Google Translate. In this study, we address this limitation by using semantic and sentiment analysis of selected LLMs for Indian languages, including Sanskrit, Telugu and Hindi. We select prominent texts that have been well translated by experts and use LLMs to generate their translations to English, and then we provide a comparison with selected expert (human) translations. Our findings suggest that while LLMs have made significant progress in translation accuracy, challenges remain in preserving sentiment and semantic integrity, especially in figurative and philosophical contexts. The sentiment analysis revealed that GPT-4o and GPT-3.5 are better at preserving the sentiments for the Bhagavad Gita (Sanskrit-English) translations when compared to Google Translate. We observed a similar trend for the case of Tamas (Hindi-English) and Maha P (Telugu-English) translations. GPT-4o performs similarly to GPT-3.5 in the translation in terms of sentiments for the three languages. We found that LLMs are generally better at translation for capturing sentiments when compared to Google Translate.