 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Language-Independent Multi-Font OCR for Arabic Script
Paper and Code
Sep 18, 2020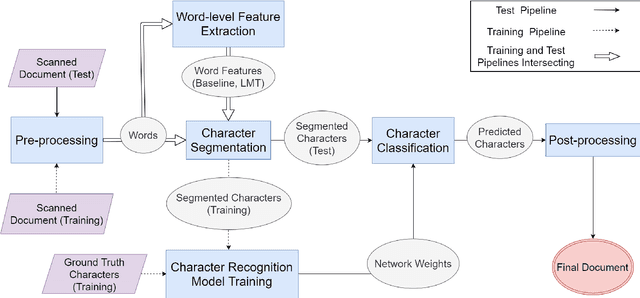



Optical Character Recognition (OCR) is the process of extracting digitized text from images of scanned documents. While OCR systems have already matured in many languages, they still have shortcomings in cursive languages with overlapping letters such as the Arabic language. This paper proposes a complete Arabic OCR system that takes a scanned image of Arabic Naskh script as an input and generates a corresponding digital document. Our Arabic OCR system consists of the following modules: Pre-processing, Word-level Feature Extraction, Character Segmentation, Character Recognition, and Post-processing. This paper also proposes an improved font-independent character segmentation algorithm that outperforms the state-of-the-art segmentation algorithms. Lastly, the paper proposes a neural network model for the character recognition task. The system has experimented on several open Arabic corpora datasets with an average character segmentation accuracy 98.06%, character recognition accuracy 99.89%, and overall system accuracy 97.94% achieving outstanding results compared to the state-of-the-art Arabic OCR systems.