Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automatic Evaluation of the WMT22 General Machine Translation Task
Paper and Code

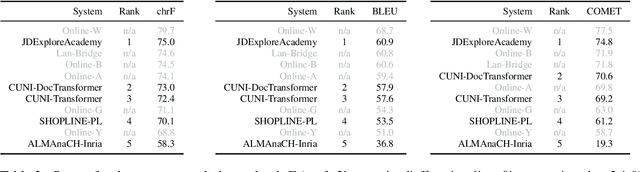


This report presents an automatic evaluation of the general machine translation task of the Seventh Conference on Machine Translation (WMT22). It evaluates a total of 185 systems for 21 translation directions including high-resource to low-resource language pairs and from closely related to distant languages. This large-scale automatic evaluation highlights some of the current limits of state-of-the-art machine translation systems. It also shows how automatic metrics, namely chrF, BLEU, and COMET, can complement themselves to mitigate their own limits in terms of interpretability and accuracy.
View paper on