 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn A*-algorithm for the Unordered Tree Edit Distance with Custom Costs
Paper and Code
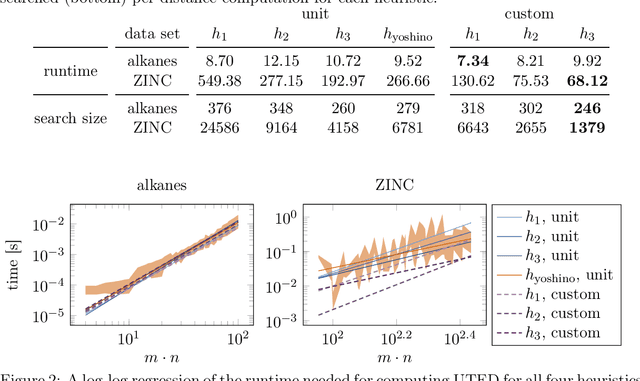
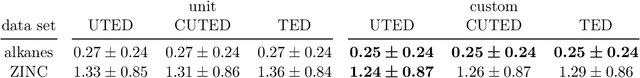
The unordered tree edit distance is a natural metric to compute distances between trees without intrinsic child order, such as representations of chemical molecules. While the unordered tree edit distance is MAX SNP-hard in principle, it is feasible for small cases, e.g. via an A* algorithm. Unfortunately, current heuristics for the A* algorithm assume unit costs for deletions, insertions, and replacements, which limits our ability to inject domain knowledge. In this paper, we present three novel heuristics for the A* algorithm that work with custom cost functions. In experiments on two chemical data sets, we show that custom costs make the A* computation faster and improve the error of a 5-nearest neighbor regressor, predicting chemical properties. We also show that, on these data, polynomial edit distances can achieve similar results as the unordered tree edit distance.