 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring
Paper and Code
Jun 13, 2024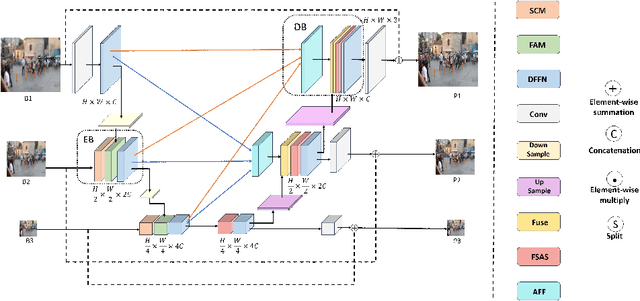
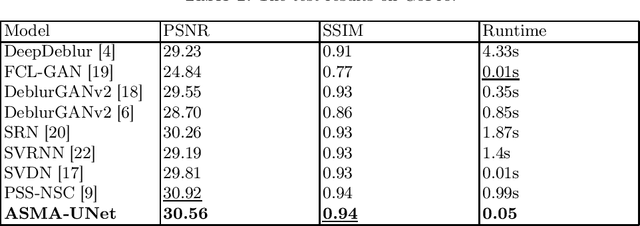
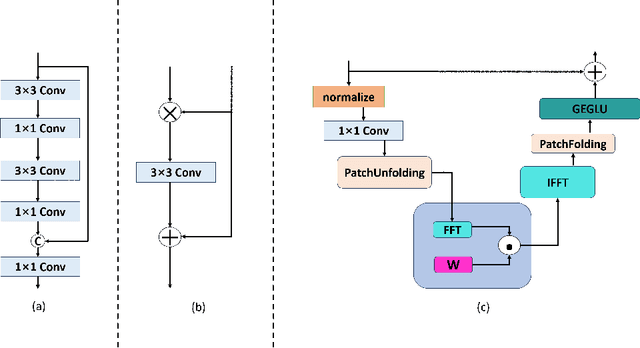

The traditional ingle-scale U-Net often leads to the loss of spatial information during deblurring, which affects the deblurring accracy. Additionally, due to the convolutional method's limitation in capturing long-range dependencies, the quality of the recovered image is degraded. To address the above problems, an asymmetric multiple scales U-net based on self-attention (AMSA-UNet) is proposed to improve the accuracy and computational complexity. By introducing a multiple-scales U shape architecture, the network can focus on blurry regions at the global level and better recover image details at the local level. In order to overcome the limitations of traditional convolutional methods in capturing the long-range dependencies of information, a self-attention mechanism is introduced into the decoder part of the backbone network, which significantly increases the model's receptive field, enabling it to pay more attention to semantic information of the image, thereby producing more accurate and visually pleasing deblurred images. What's more, a frequency domain-based computation method was introduced to reduces the computation amount. The experimental results demonstrate that the proposed method exhibits significant improvements in both accuracy and speed compared to eight excellent methods