 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlirector: Alignment-Enhanced Chinese Grammatical Error Corrector
Paper and Code

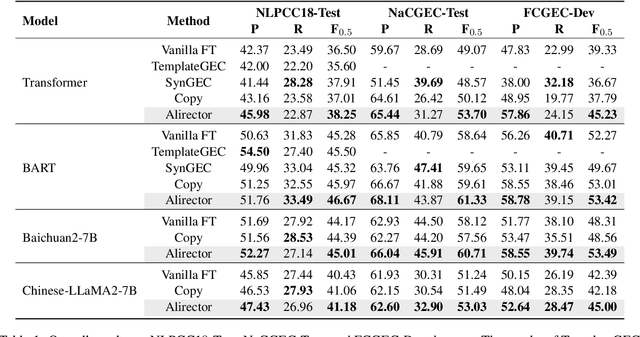
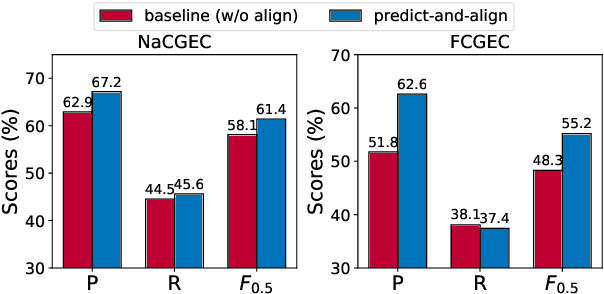

Chinese grammatical error correction (CGEC) faces serious overcorrection challenges when employing autoregressive generative models such as sequence-to-sequence (Seq2Seq) models and decoder-only large language models (LLMs). While previous methods aim to address overcorrection in Seq2Seq models, they are difficult to adapt to decoder-only LLMs. In this paper, we propose an alignment-enhanced corrector for the overcorrection problem that applies to both Seq2Seq models and decoder-only LLMs. Our method first trains a correction model to generate an initial correction of the source sentence. Then, we combine the source sentence with the initial correction and feed it through an alignment model for another round of correction, aiming to enforce the alignment model to focus on potential overcorrection. Moreover, to enhance the model's ability to identify nuances, we further explore the reverse alignment of the source sentence and the initial correction. Finally, we transfer the alignment knowledge from two alignment models to the correction model, instructing it on how to avoid overcorrection. Experimental results on three CGEC datasets demonstrate the effectiveness of our approach in alleviating overcorrection and improving overall performance.