 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregated Text Transformer for Scene Text Detection
Paper and Code
Nov 25, 2022


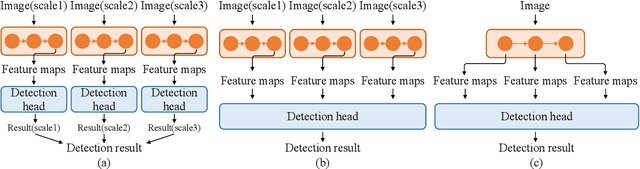
This paper explores the multi-scale aggregation strategy for scene text detection in natural images. We present the Aggregated Text TRansformer(ATTR), which is designed to represent texts in scene images with a multi-scale self-attention mechanism. Starting from the image pyramid with multiple resolutions, the features are first extracted at different scales with shared weight and then fed into an encoder-decoder architecture of Transformer. The multi-scale image representations are robust and contain rich information on text contents of various sizes. The text Transformer aggregates these features to learn the interaction across different scales and improve text representation. The proposed method detects scene texts by representing each text instance as an individual binary mask, which is tolerant of curve texts and regions with dense instances. Extensive experiments on public scene text detection datasets demonstrate the effectiveness of the proposed framework.