Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffinity and Diversity: Quantifying Mechanisms of Data Augmentation
Paper and Code


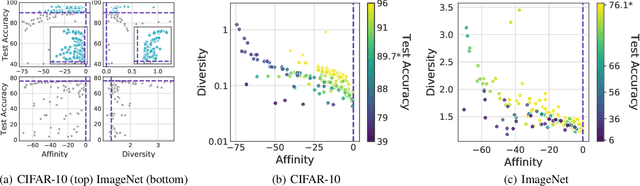

Though data augmentation has become a standard component of deep neural network training, the underlying mechanism behind the effectiveness of these techniques remains poorly understood. In practice, augmentation policies are often chosen using heuristics of either distribution shift or augmentation diversity. Inspired by these, we seek to quantify how data augmentation improves model generalization. To this end, we introduce interpretable and easy-to-compute measures: Affinity and Diversity. We find that augmentation performance is predicted not by either of these alone but by jointly optimizing the two.
* 10 pages, 7 figures
View paper on