 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples for DNA Classification
Paper and Code
Sep 29, 2024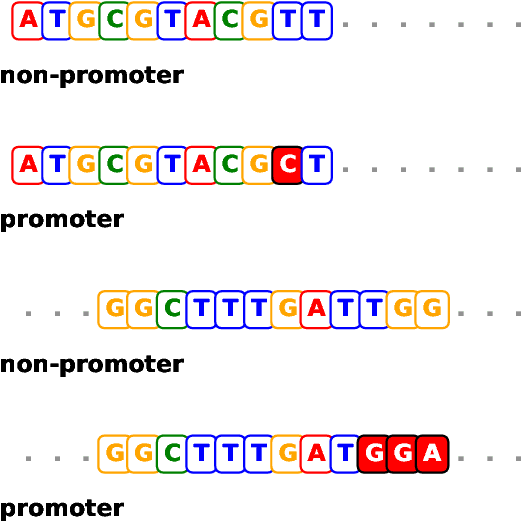

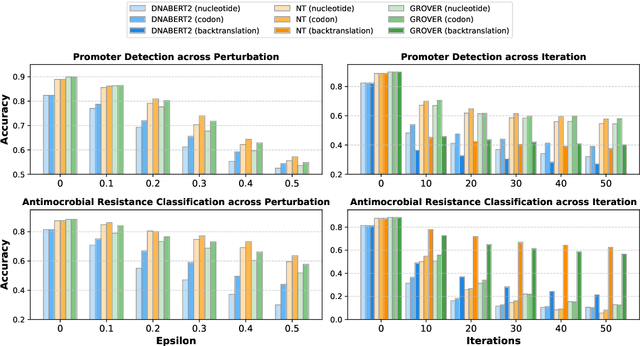
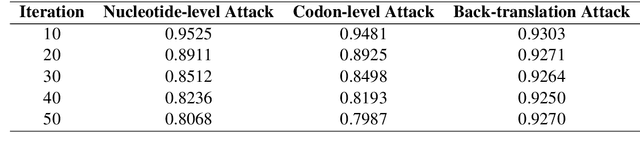
Pre-trained language models such as DNABERT2 and Nucleotide Transformer, which are trained on DNA sequences, have shown promising performance in DNA sequence classification tasks. The classification ability of these models stems from language models trained on vast amounts of DNA sequence samples, followed by fine-tuning with relatively smaller classification datasets. However, these text-based systems are not robust enough and can be vulnerable to adversarial examples. While adversarial attacks have been widely studied in text classification, there is limited research in DNA sequence classification. In this paper, we adapt commonly used attack algorithms in text classification for DNA sequence classification. We evaluated the impact of various attack methods on DNA sequence classification at the character, word, and sentence levels. Our findings indicate that actual DNA language model sequence classifiers are vulnerable to these attacks.