 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks and Defense on Texts: A Survey
Paper and Code
Jun 14, 2020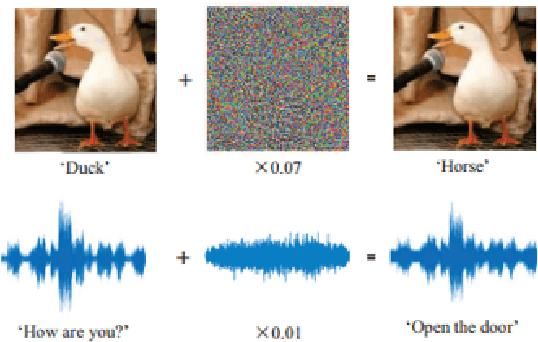
Deep learning models have been used widely for various purposes in recent years in object recognition, self-driving cars, face recognition, speech recognition, sentiment analysis, and many others. However, in recent years it has been shown that these models possess weakness to noises which force the model to misclassify. This issue has been studied profoundly in the image and audio domain. Very little has been studied on this issue concerning textual data. Even less survey on this topic has been performed to understand different types of attacks and defense techniques. In this manuscript, we accumulated and analyzed different attacking techniques and various defense models to provide a more comprehensive idea. Later we point out some of the interesting findings of all papers and challenges that need to be overcome to move forward in this field.