Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Bias in Visualization Recommenders by Identifying Trends in Training Data: Improving VizML Through a Statistical Analysis of the Plotly Community Feed
Paper and Code
Mar 09, 2022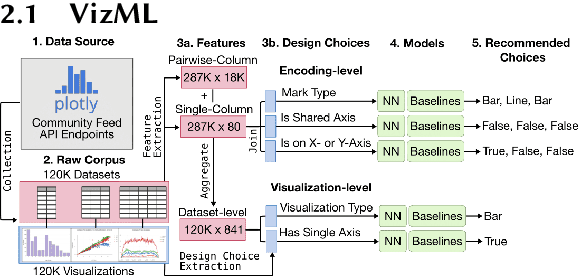

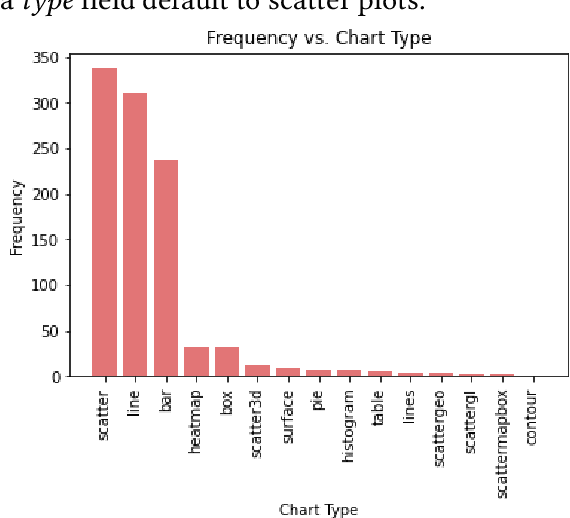
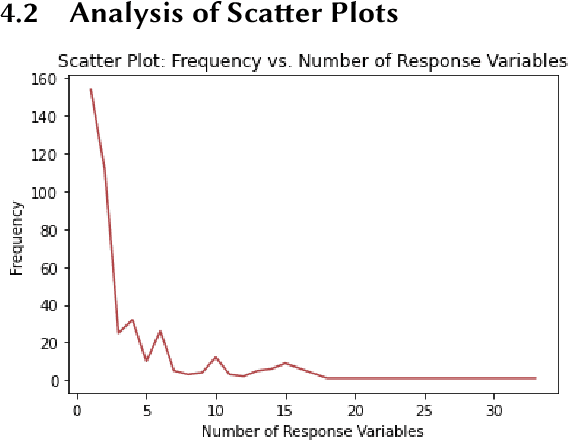
Machine learning is a promising approach to visualization recommendation due to its high scalability and representational power. Researchers can create a neural network to predict visualizations from input data by training it over a corpus of datasets and visualization examples. However, these machine learning models can reflect trends in their training data that may negatively affect their performance. Our research project aims to address training bias in machine learning visualization recommendation systems by identifying trends in the training data through statistical analysis.
View paper on