 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdd a SideNet to your MainNet
Paper and Code
Jul 14, 2020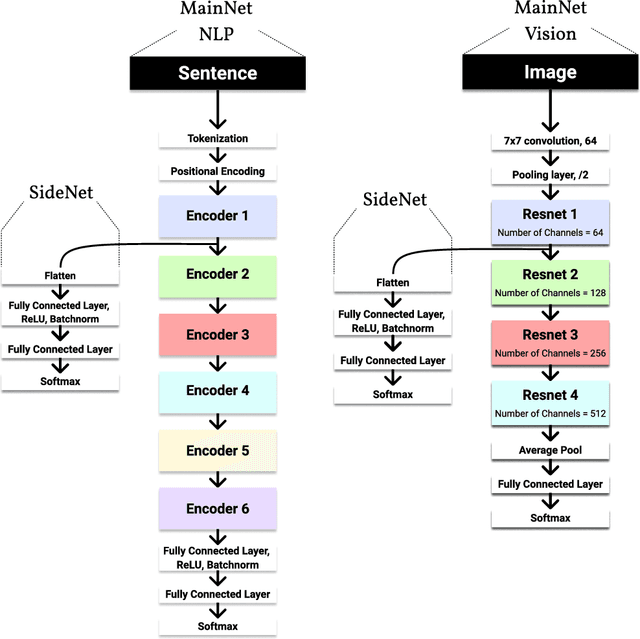

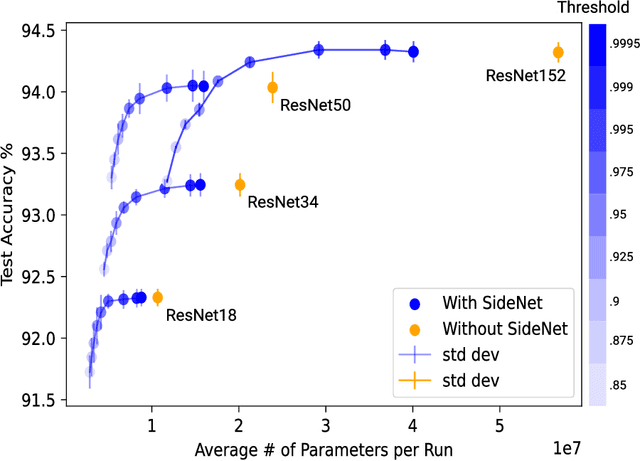

As the performance and popularity of deep neural networks has increased, so too has their computational cost. There are many effective techniques for reducing a network's computational footprint (quantisation, pruning, knowledge distillation), but these lead to models whose computational cost is the same regardless of their input. Our human reaction times vary with the complexity of the tasks we perform: easier tasks (e.g. telling apart dogs from boat) are executed much faster than harder ones (e.g. telling apart two similar looking breeds of dogs). Driven by this observation, we develop a method for adaptive network complexity by attaching a small classification layer, which we call SideNet, to a large pretrained network, which we call MainNet. Given an input, the SideNet returns a classification if its confidence level, obtained via softmax, surpasses a user determined threshold, and only passes it along to the large MainNet for further processing if its confidence is too low. This allows us to flexibly trade off the network's performance with its computational cost. Experimental results show that simple single hidden layer perceptron SideNets added onto pretrained ResNet and BERT MainNets allow for substantial decreases in compute with minimal drops in performance on image and text classification tasks. We also highlight three other desirable properties of our method, namely that the classifications obtained by SideNets are calibrated, complementary to other compute reduction techniques, and that they enable the easy exploration of compute accuracy space.