 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating DNN Training with Structured Data Gradient Pruning
Paper and Code
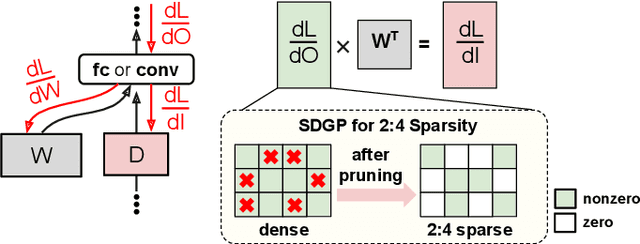
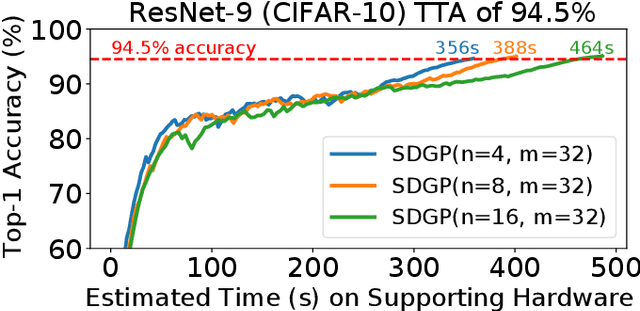
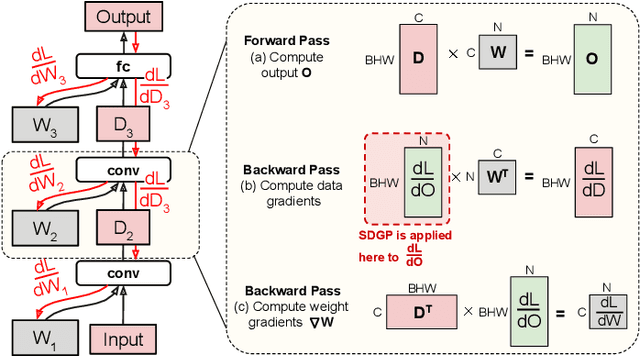
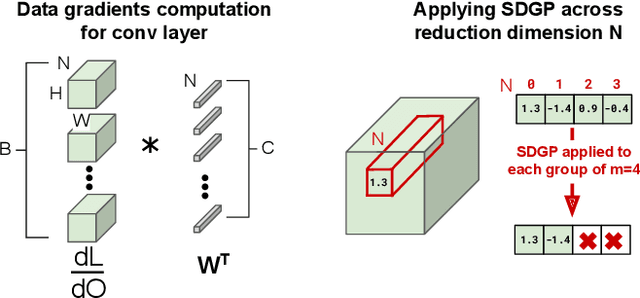
Weight pruning is a technique to make Deep Neural Network (DNN) inference more computationally efficient by reducing the number of model parameters over the course of training. However, most weight pruning techniques generally does not speed up DNN training and can even require more iterations to reach model convergence. In this work, we propose a novel Structured Data Gradient Pruning (SDGP) method that can speed up training without impacting model convergence. This approach enforces a specific sparsity structure, where only N out of every M elements in a matrix can be nonzero, making it amenable to hardware acceleration. Modern accelerators such as the Nvidia A100 GPU support this type of structured sparsity for 2 nonzeros per 4 elements in a reduction. Assuming hardware support for 2:4 sparsity, our approach can achieve a 15-25\% reduction in total training time without significant impact to performance. Source code and pre-trained models are available at \url{https://github.com/BradMcDanel/sdgp}.