 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Convolutional Neural Networks via Activation Map Compression
Paper and Code

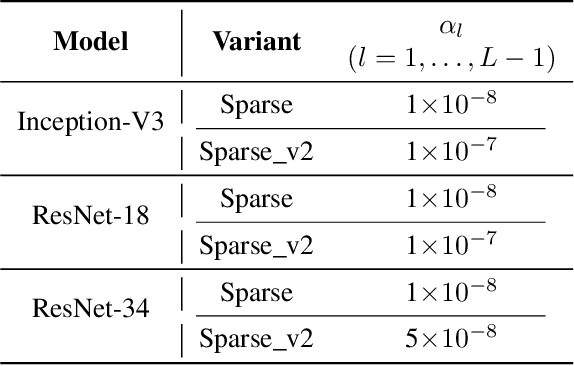
The deep learning revolution brought us an extensive array of neural network architectures that achieve state-of-the-art performance in a wide variety of Computer Vision tasks including among others classification, detection and segmentation. In parallel, we have also been observing an unprecedented demand in computational and memory requirements, rendering the efficient use of neural networks in low-powered devices virtually unattainable. Towards this end, we propose a three-stage compression and acceleration pipeline that sparsifies, quantizes and entropy encodes activation maps of Convolutional Neural Networks. Sparsification increases the representational power of activation maps leading to both acceleration of inference and higher model accuracy. Inception-V3 and MobileNet-V1 can be accelerated by as much as $1.6\times$ with an increase in accuracy of $0.38\%$ and $0.54\%$ on the ImageNet and CIFAR-10 datasets respectively. Quantizing and entropy coding the sparser activation maps lead to higher compression over the baseline, reducing the memory cost of the network execution. Inception-V3 and MobileNet-V1 activation maps, quantized to $16$ bits, are compressed by as much as $6\times$ with an increase in accuracy of $0.36\%$ and $0.55\%$ respectively.